What does pretraining on unlabeled text actually teach an LLM?
Pretraining on unlabeled text teaches an LLM to model the statistical structure of language well enough that it can predict plausible continuations across many different contexts.
That may sound narrow, but it turns out to be a very rich learning signal. When a model repeatedly learns to predict the next token across books, articles, code, conversations, and other text, it is forced to internalize many kinds of regularities.
At a minimum, pretraining teaches:
- syntax, such as word order, agreement, and grammatical patterns
- semantics, such as which words and phrases tend to go together in meaning
- style, such as different tones, formats, and registers
- discourse structure, such as how explanations, stories, and arguments unfold
- factual associations, such as many recurring relationships and patterns found in text
The mechanism is still next-token prediction. The model reads a prefix and learns to place higher probability on the actual continuation found in the training corpus.
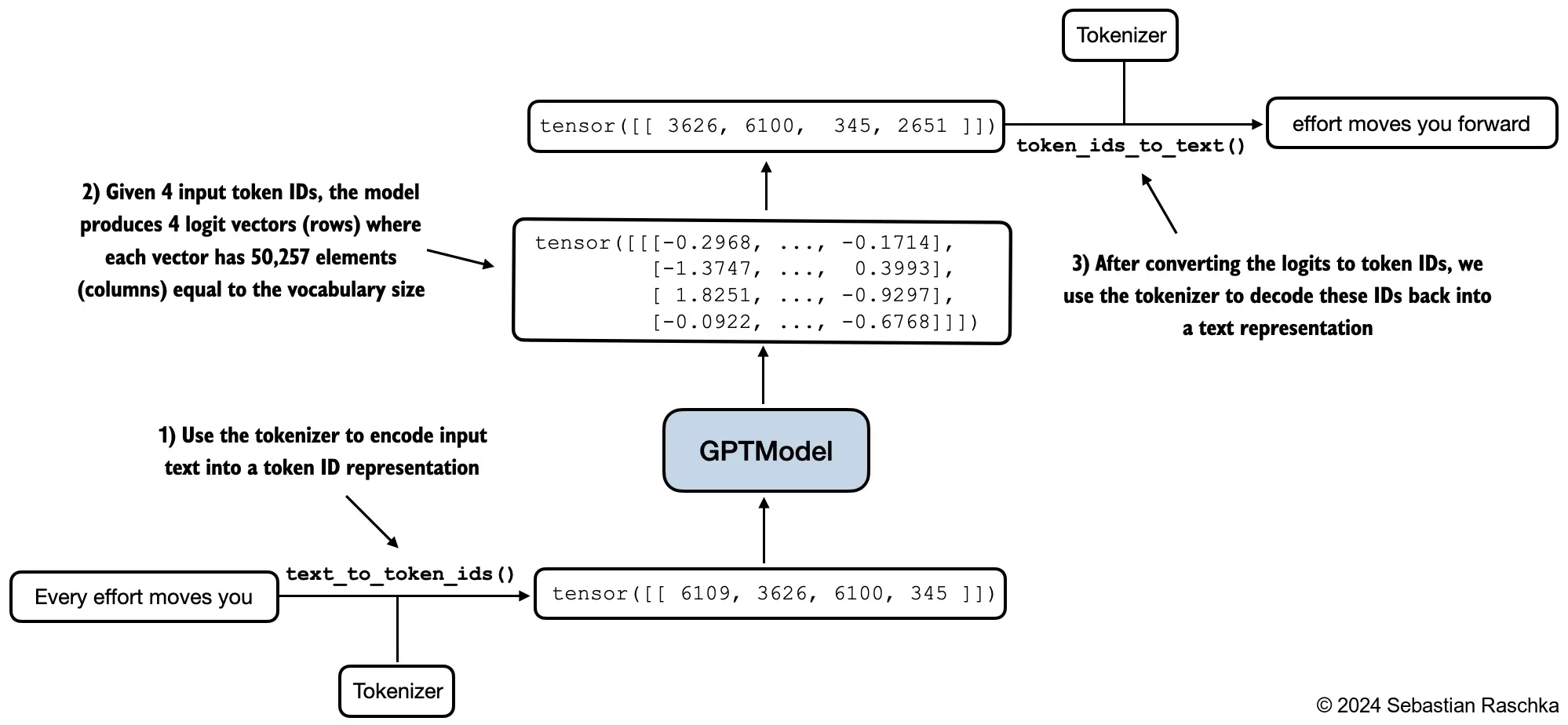
Because this happens over enormous amounts of text, the model gradually picks up reusable capabilities. For example, a model that has seen many question-answer pairs, summaries, code snippets, definitions, translations, and structured explanations can often perform related tasks later from prompting alone, even though pretraining never labeled those tasks explicitly.
This is why pretraining is more than memorizing a large phrase table. To perform well on next-token prediction, the model has to build internal representations that help it generalize across contexts it has never seen exactly before.
At the same time, it is important to be precise about what pretraining does not directly teach. A pretrained base model is usually not optimized to be especially helpful, harmless, concise, or instruction-following. It is optimized to continue text in ways that are statistically plausible under its training data.
That is why a pretrained model can often:
- complete text well
- imitate styles well
- answer many questions surprisingly well
but still struggle with:
- following an instruction format reliably
- choosing the most user-helpful answer style
- staying aligned with application-specific preferences
The repo emphasizes this distinction in chapter 7: pretraining makes the model good at text continuation, while later instruction finetuning teaches it to behave more like an assistant.
Another important point is that pretraining uses unlabeled data. No one has to annotate the next token. The training targets come from the text itself, which makes it feasible to learn from very large corpora.

So when people say pretraining teaches an LLM “knowledge,” the most accurate way to think about it is this: pretraining teaches a model a very broad predictive model of language and text-distributed regularities. Many useful capabilities emerge from that objective, but they are all rooted in becoming good at predicting what tends to come next.
In short, pretraining on unlabeled text teaches an LLM the patterns of language, structure, style, and many factual and procedural regularities by forcing it to become a strong next-token predictor over massive text corpora.