What are the different approaches for dealing with limited labeled data in supervised machine learning settings?
Next to collecting more data, there are several methods more or less related to regular supervised learning that we can use in limited-labeled data regimes.
1) Label more data
Collecting additional training examples is often the best way to improve the performance of a mode. However, this is often not feasible in practice. Listed below are various alternative approaches.
2) Bootstrapping the data
It can be helpful to “bootstrap” the data by generating modified (augmented) or artificial (synthetic) training examples to boost the performance of the predictive model.
Of course, improving the quality of data can also lead to improved predictive performance of a model.
3) Transfer learning
Transfer learning describes training a model on a general dataset (e.g., ImageNet) and then fine-tuning the pre-trained target dataset (e.g., a specific dataset consisting of different bird species). Transfer learning is usually done in the context of deep learning, where model weights can be updated. This is in contrast to tree-based methods since most decision tree algorithms are nonparametric models that do not support iterative training or parameter updates.
4) Self-supervised learning
Similar to transfer learning, self-supervised learning, the model is pretrained on a different task before it is fine-tuned to a target task for which only limited data exists. However, in contrast to transfer learning, self-supervised learning usually relies on label information that can be directly and automatically extracted from unlabeled data. Hence, self-supervised learning is also often called unsupervised pretraining. Common examples include “next word” (e.g., used in GPT) or “masked word” (e.g., used in BERT) prediction in language modeling.
5) Active learning
In active learning, we typically involve manual labelers or users for feedback during the learning process. However, instead of labeling the entire dataset upfront, active learning includes a prioritization scheme for suggesting unlabeled data points for labeling that maximize the machine learning model’s performance.
6) Few-shot learning
In a few-shot learning scenario, we often deal with extremely small datasets where we usually only have a handful of examples per class. In research contexts, 1-shot (1 example per class) and 5-shot (5 examples per class) are very common.
7) Meta-learning
We can think of meta-learning as “learning to learn” – we develop methods that learn how machine learning algorithms can best learn from data. Over the years, the machine learning community developed several approaches for meta-learning. To further complicate matters, meta-learning can refer to different processes.
Meta-learning is one of the main subcategories of few-shot learning (mentioned above). Here, the focus is on learning a good feature extraction module.
Another branch of meta-learning, unrelated to the few-shot learning approach above, is focused on extracting meta-data (also called meta-features) from datasets for supervised learning tasks.
8) Weakly supervised learning
Weakly supervised learning is a procedure where we use an external label source to generate labels for an unlabeled dataset. Often, the labels created by a weakly supervised labeling function are more noisy or inaccurate than those produced by a human or domain expert; hence, the term weakly supervised.
9) Semi-supervised learning
Semi-supervised learning is closely related to weakly supervised learning described above: we create labels for unlabeled instances in the dataset. The main difference between weakly supervised and semi-supervised learning is how we create the labels.
10) Self-training
Self-training is a category that falls somewhere between semi-supervised learning and weakly supervised learning. In self-training, we train a model or adopt an existing model to label the dataset. This model is also referred to as a pseudo-labeler.
11) Multi-task learning
Multi-task learning trains neural networks on multiple, ideally related tasks. For example, suppose we are training a classifier to detect spam emails; here, spam classification is the main task. In multi-task learning, we can add one or more related tasks the model has to solve. These additional tasks are also referred to as auxiliary tasks. If the main task is email spam classification, an auxiliary task could be classifying the email’s topic or language.
12) Multi-modal learning
While multi-task learning involves training a model with multiple tasks and loss functions, multi-modal learning focuses on incorporating multiple types of input data.
13) Inductive biases
Choosing models with stronger inductive biases can help to lower data requirements by making assumptions about the structure of the data. For example, due to their inductive biases, convolutional networks require less data than vision transformers.
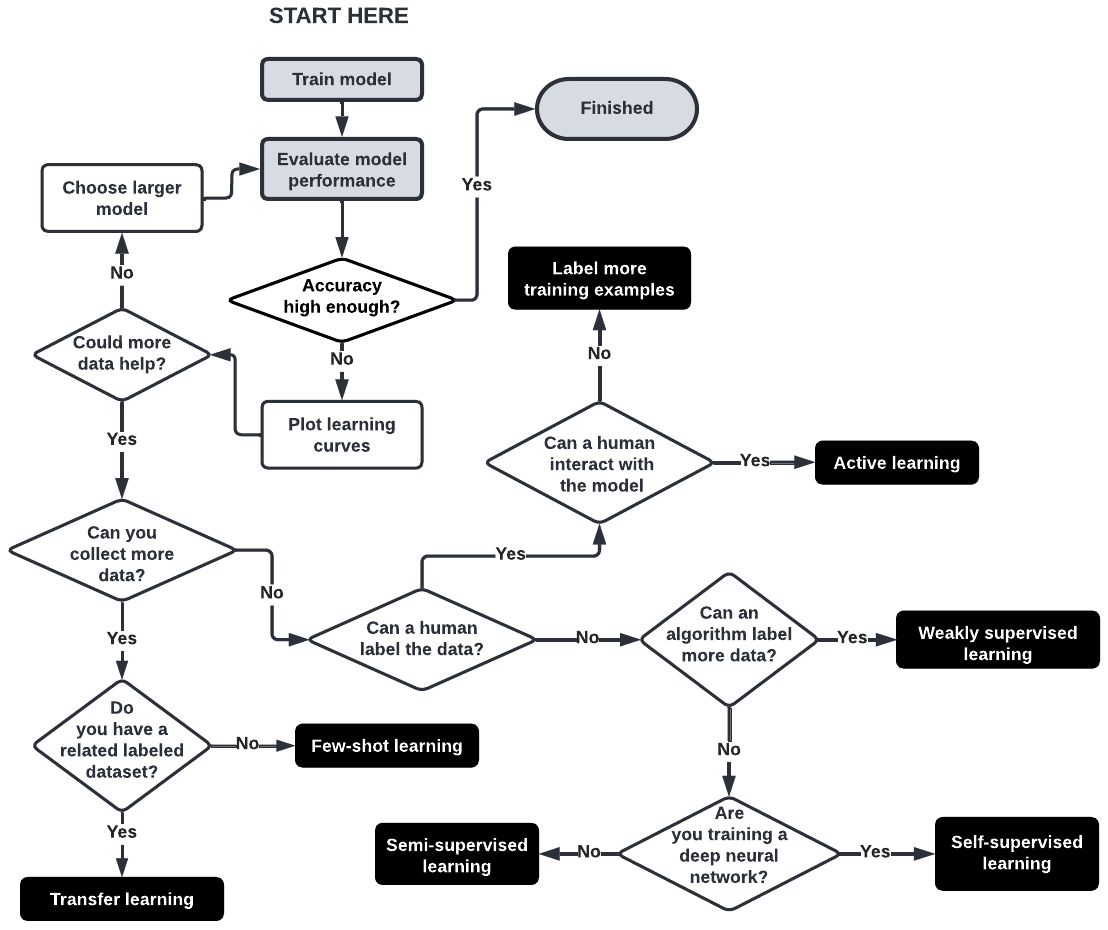
Which techniques should we use?
Now that we covered several techniques for lowering the data requirements, which ones should we use?
The figure below provides an overview that can be used for guidance.
If you like this content and you are looking for similar, an extended and much more polished version of this Q & A is available in my book Machine Learning Q and AI.