What does `torch.compile` actually help with in LLM workloads?
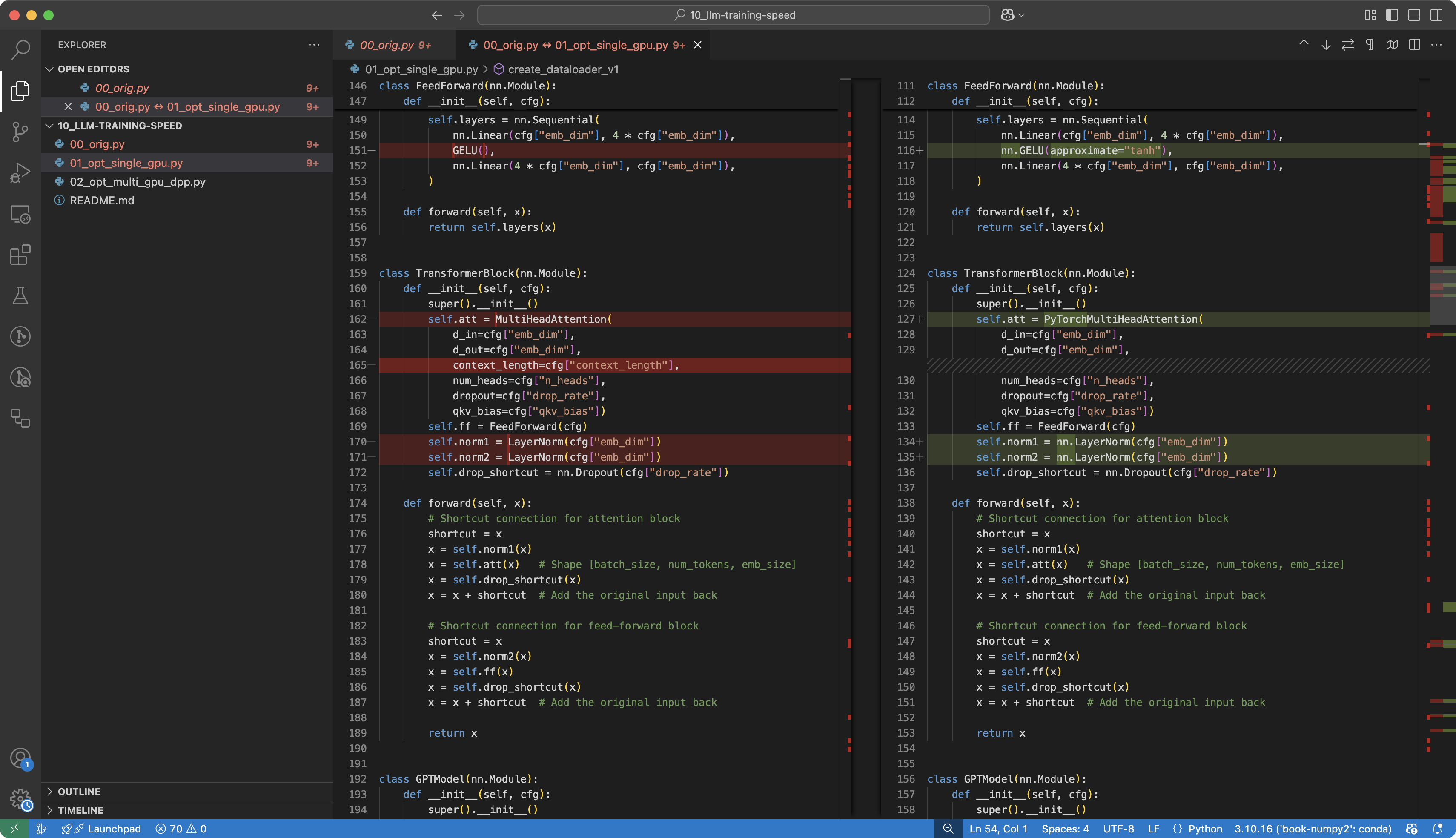
torch.compile helps LLM workloads by turning ordinary eager PyTorch execution into a more optimized compiled path. In practice, that can reduce Python overhead, fuse operations, and generate faster kernels for repeated model execution.
The important point is that it does not change the model’s math. It changes how PyTorch runs that math.
In LLM workloads, that matters because the same forward pass is repeated many times. Once PyTorch can treat that repeated computation as a stable graph, it has more room to optimize.
Typical benefits include:
- less Python interpreter overhead
- better operator fusion
- more efficient kernels for repeated execution
That said, torch.compile is not a free win in every situation. It has an upfront compilation cost, and the first iterations may be much slower before the optimized path kicks in.
The repo explicitly notes this behavior: once compilation was enabled, the early timing numbers looked worse at first, but later generation or training steps sped up substantially.

So the best use cases are usually:
- repeated runs of the same model
- relatively stable tensor shapes
- long enough workloads to amortize warm-up cost
The tradeoff is that compilation can be more fragile across environments and may not be worth it for short-lived or highly dynamic workloads.
In short, torch.compile helps LLM workloads by compiling repeated PyTorch execution into a more optimized form, which can improve throughput after the warm-up phase, especially when the model is run many times with stable shapes.