How should someone progress from a simple GPT implementation to a modern production-style LLM stack?
A good way to progress from a simple GPT implementation to a modern production-style LLM stack is to build capability in layers rather than trying to copy the final industrial system all at once.
The repo itself already suggests a strong learning path:
- start with tokenization and embeddings
- implement attention and a basic GPT-style decoder
- train with next-token prediction
- add generation and evaluation
- add supervised finetuning and instruction finetuning
- add preference tuning
- only then layer in modern architecture and systems optimizations

After the simple GPT baseline is working, the next modern additions usually include:
- KV cache for faster inference
- RoPE and RMSNorm
- SwiGLU feed-forward blocks
- GQA and possibly sliding-window attention
- LoRA for cheaper adaptation
- FlashAttention,
bfloat16, andtorch.compile - memory-efficient checkpoint loading
The reason for this order is practical. If the baseline is not correct and understandable, adding every modern optimization at once just makes debugging harder.
The repo’s architecture-comparison material reinforces that modern LLM systems are mostly built by refining the basic GPT-style recipe, not by abandoning it.
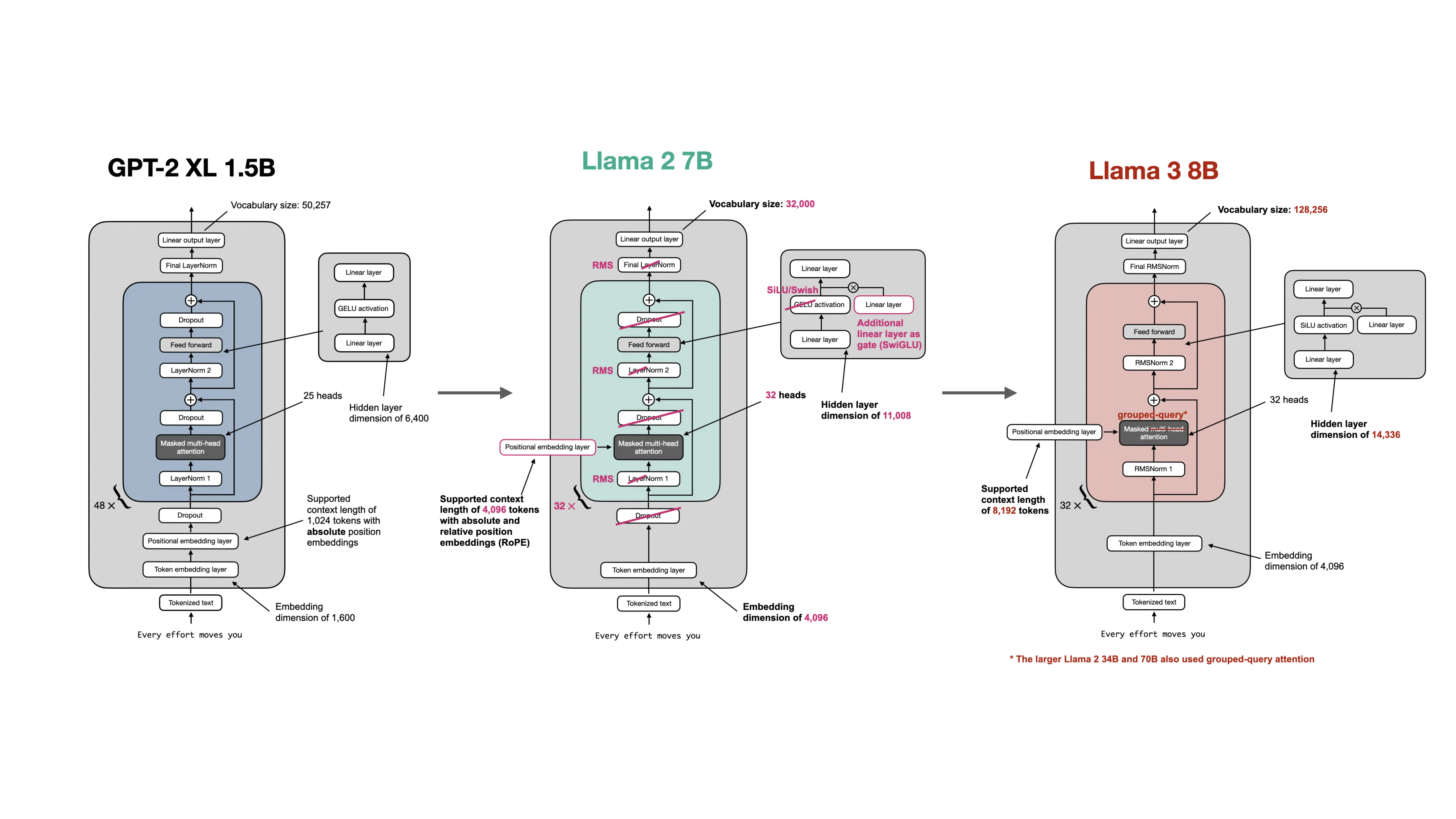
So the right progression is:
- first learn the core model deeply
- then learn finetuning and evaluation
- then add modern architecture choices
- finally add production-oriented systems optimizations
In short, someone should progress from a simple GPT implementation to a production-style LLM stack step by step: get the baseline model and training loop right first, then add finetuning and evaluation, and only after that layer in modern architecture and performance engineering.