What is self-supervised learning and when is it useful?
Self-supervised learning is a pretraining procedure that lets neural networks leverage large unlabeled datasets in a supervised fashion.
Self-supervised is related to transfer learning. Suppose we are interested in training an image classifier to classify bird species. In transfer learning we would pretrain a convolutional neural network on ImageNet. After pretraining on the general ImageNet dataset, we would take the pretrained model and train it on the smaller, more specific target dataset that contains the bird species of interest.
![]()
Self-supervised learning is an alternative approach to transfer learning where we don’t pretrain the model on labeled but unlabeled data. We consider an unlabeled dataset for which we do not have label information. We then find a way to obtain labels from the dataset’s structure to formulate a prediction task for the neural network. These self-supervised training tasks are also called pretext tasks.
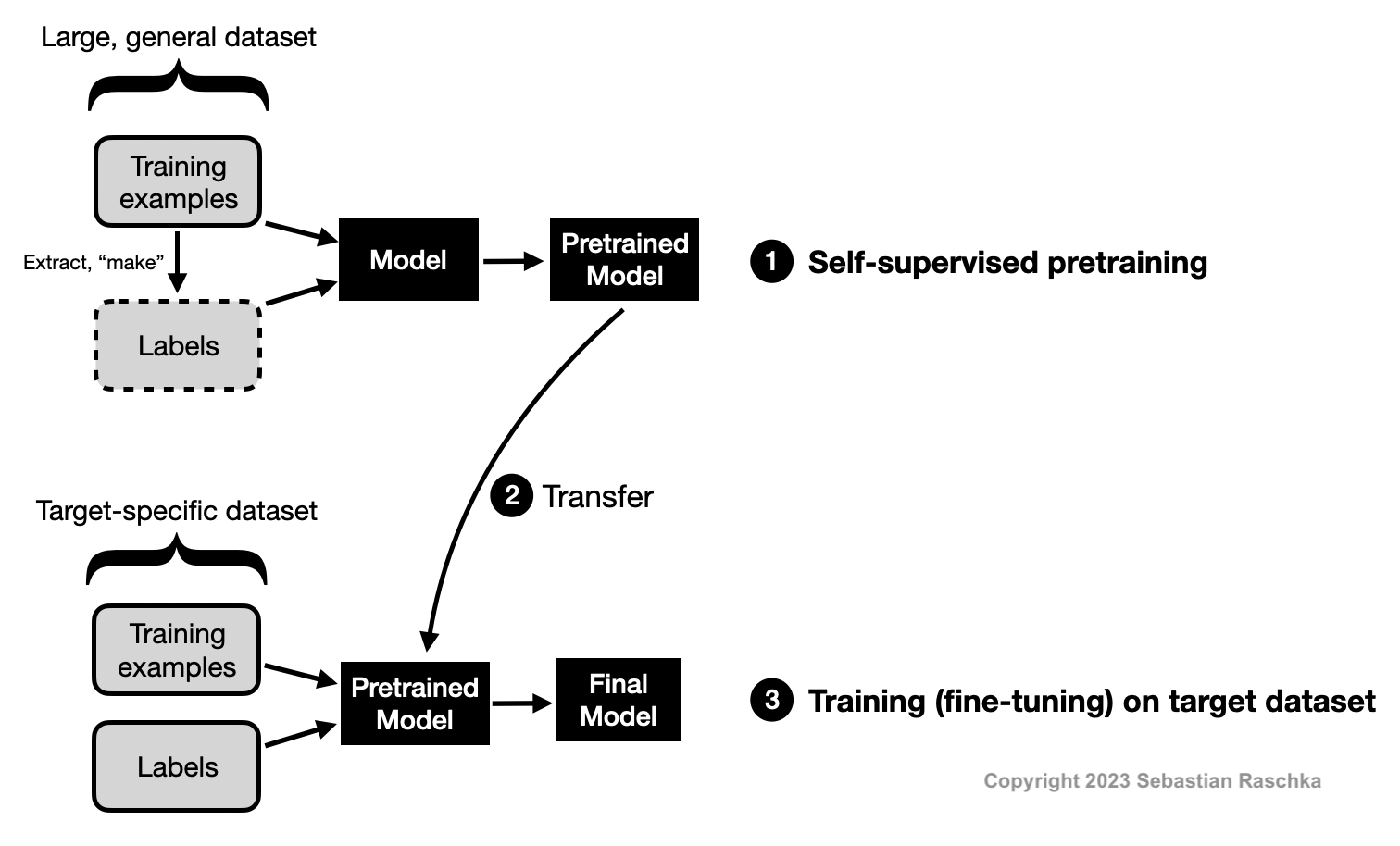
Such a self-supervised learning task could be a “missing-word” prediction in a natural language processing context. For example, given the sentence “It is beautiful and sunny outside,” we can mask out the word “sunny,” feed the network the input It is beautiful and [MASK] outside,” and have the network predict the missing word in the “[MASK]” location. Similarly, we could remove image patches in a computer vision context and have the neural network fill in the blanks. Note that these are just two examples of self-supervised learning tasks. Many more methods and paradigms for self-supervised learning exist.
In sum, we can think of self-supervised learning on the pretext task as representation learning. We can then take the pretrained model to finetune it on the target task (also known as the downstream task).
When is self-supervised learning useful?
Large neural network architectures require large amounts of labeled data to perform and generalize well. However, for many problem areas, we do not have access to large labeled datasets. With self-supervised learning, we can leverage unlabeled data. Hence, self-supervised learning is likely useful if we work with large neural networks and we only have a limited amount of labeled training data.
Transformer-based architectures that form the basis of large language models and vision transformers are known to require self-supervised learning for pretraining to perform well.
For small neural network models, for example, multi-layer perceptrons with two or three layers, self-supervised learning is typically considered neither useful nor necessary. However, examples of self-supervised learning for multi-layer perceptrons and tabular datasets do exist.
Other contexts where self-supervised learning is not useful are traditional machine learning with nonparametric models such as tree-based random forests or gradient boosting. Conventional tree-based methods do not have a fixed parameter structure (in contrast to the weight matrices, for example). Thus, conventional tree-based methods are not capable of transfer learning and incompatible with self-supervised learning.
This is an abbreviated answer and excerpt from my book Machine Learning Q and AI, which contains a more verbose version with additional illustrations.