What is self-attention, and why is it the core mechanism behind modern LLMs?
Self-attention is the mechanism that lets each token in a sequence look at other tokens in the same sequence and decide which ones matter most for building its representation.
Instead of processing text with a fixed local rule, self-attention computes a new representation for each token as a weighted combination of other token representations. The weights are not fixed in advance. They are computed dynamically from the current sequence, which is why the mechanism is so flexible.
At a high level, self-attention works like this:
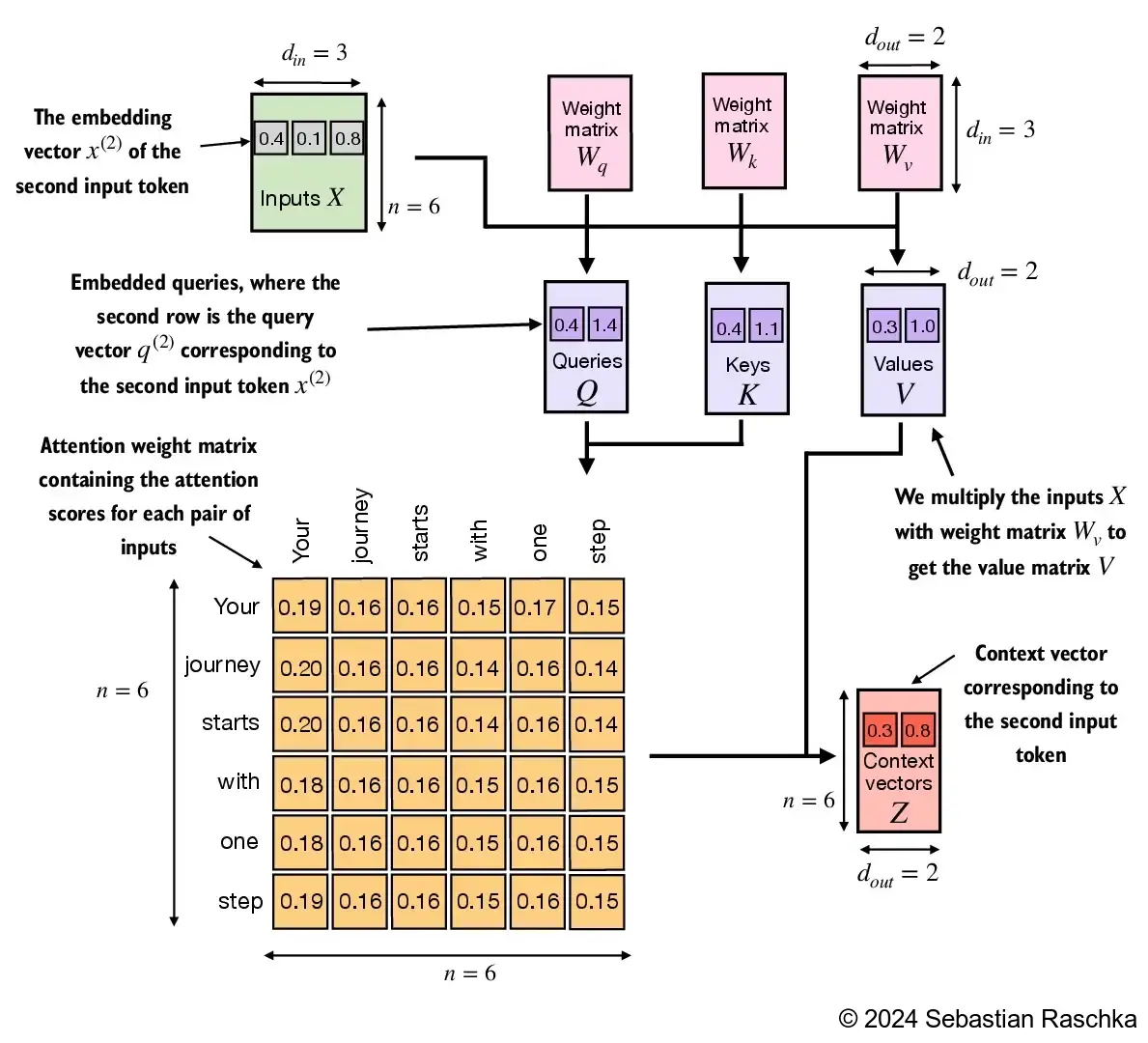
- Each token is turned into a query, a key, and a value vector.
- The query of the current token is compared with the keys of other tokens.
- These similarity scores are normalized into attention weights.
- The output for the token is the weighted sum of the value vectors.
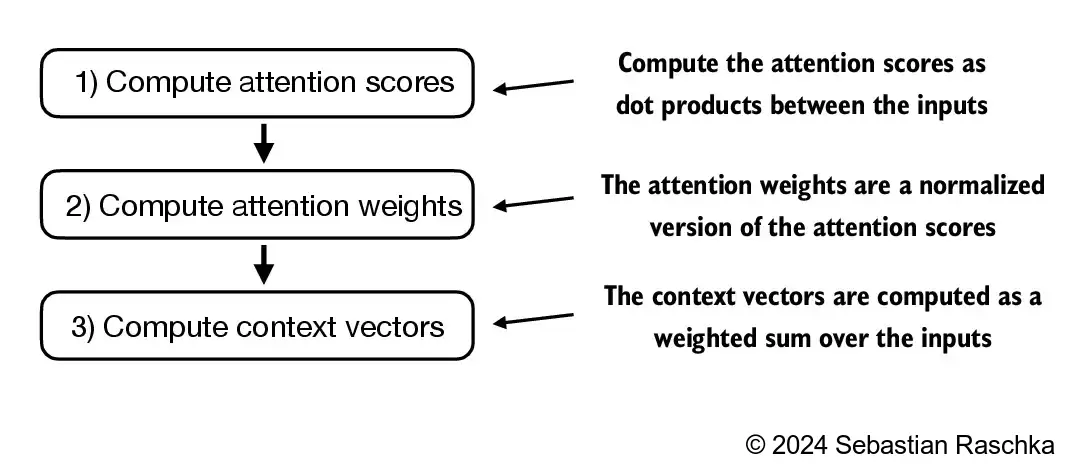
The result is a context vector: a representation of the current token that already incorporates relevant information from other positions in the sequence.
This is the core mechanism behind modern LLMs because it solves several problems that older language-modeling approaches struggled with.
First, it is content-dependent. A token can attend strongly to different earlier words depending on the sentence. For example, in one context a word may need to attend to the subject of a sentence; in another, it may need to attend to a nearby modifier or a much earlier definition.
Second, it handles long-range dependencies much better than classic n-gram models and often more directly than recurrent models. A token does not have to pass information step by step through many recurrent updates. It can directly assign weight to relevant earlier tokens.
Third, self-attention is highly parallelizable during training. All token positions in a sequence can compute their attention interactions in matrix form, which is a major reason transformer models scale so effectively.
Fourth, it creates a strong general-purpose inductive bias for language. Language understanding often depends on relationships such as reference, agreement, topic continuation, explanation, and retrieval of earlier facts. Self-attention is well suited to modeling these relationships because it explicitly computes token-to-token interactions.
Of course, self-attention by itself is not the entire model. Modern LLMs combine it with embeddings, positional information, feed-forward layers, normalization, and residual connections. But self-attention is the part that gives transformers their distinctive ability to build rich context-sensitive representations.
That is why it sits at the center of GPT, Llama, Qwen, Gemma, and most other modern LLM families. Once a model can repeatedly update each token using information from the rest of the sequence, stacked transformer layers can build increasingly abstract representations and better next-token predictions.
In short, self-attention is the mechanism that lets each token selectively gather information from other tokens in the same sequence, and it is the core of modern LLMs because it is flexible, expressive, and easy to scale.