Why do many modern LLMs use RMSNorm instead of LayerNorm?
Many modern LLMs use RMSNorm instead of LayerNorm because it gives them most of the practical stabilization benefit of normalization with a slightly simpler computation.
In a transformer block, normalization helps keep activations well behaved as they pass through many residual layers. Without that, training deep models becomes harder and less stable.
The difference is that LayerNorm does two things:
- it recenters activations by subtracting the mean
- it rescales them using the variance
RMSNorm keeps only the rescaling part. It normalizes activations based on their root-mean-square magnitude and skips the mean-subtraction step.
That sounds like a small change, but in large decoder-only models these small simplifications add up. Fewer operations can mean lower overhead, cleaner kernels, and a slightly more efficient model design.
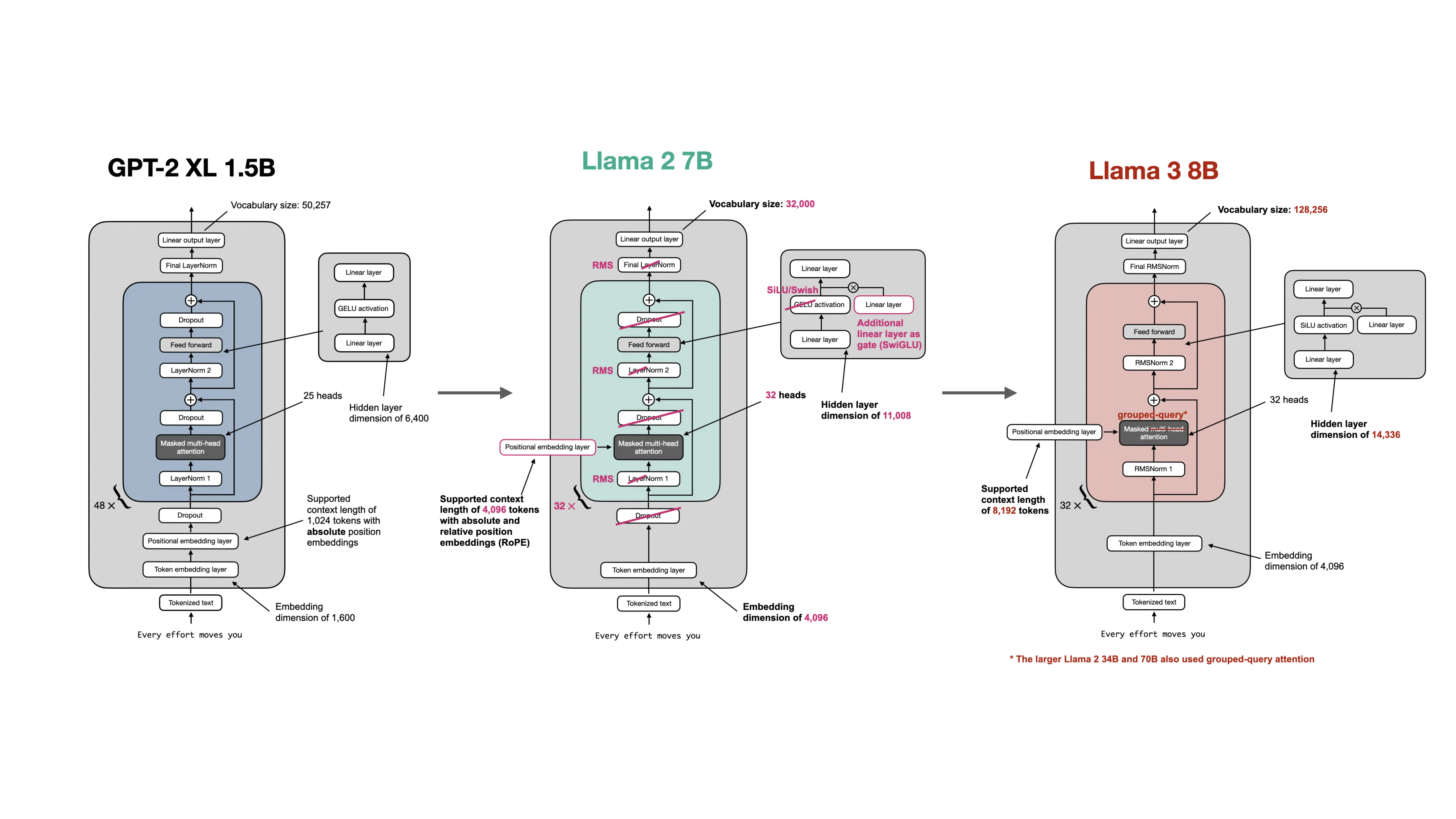
This is why RMSNorm became common in Llama-style architectures. The point is not that LayerNorm was fundamentally wrong. Older GPT-style models trained successfully with it. The point is that once practitioners pushed model depth and deployment scale much further, they started replacing parts that looked more expensive than necessary.
In practice, RMSNorm is attractive because:
- it is simpler than LayerNorm
- it usually works well in pre-norm transformer stacks
- it fits the broader modern trend toward efficiency-oriented architectural cleanup
The repo’s modern architecture material shows this as part of a broader package of changes: Llama-family models did not just switch normalization. They also moved to RoPE, SwiGLU, and bias-free linear layers. RMSNorm is one piece of that modernization.
It is also important not to overstate the difference. RMSNorm does not magically transform model quality on its own. It is better understood as a pragmatic architectural refinement that helps modern LLMs train and run efficiently at scale.
In short, many modern LLMs use RMSNorm instead of LayerNorm because it preserves the useful magnitude-normalization behavior while removing the mean-centering step, which makes the transformer block slightly simpler and better aligned with efficiency-focused large-scale model design.