What is the difference between pretraining, finetuning, and instruction finetuning?
These three stages differ mainly in data, objective, and goal.
Pretraining is the broad first stage. The model is trained on a very large corpus of mostly unlabeled text with a next-token prediction objective. The goal is to learn a strong general-purpose language model.
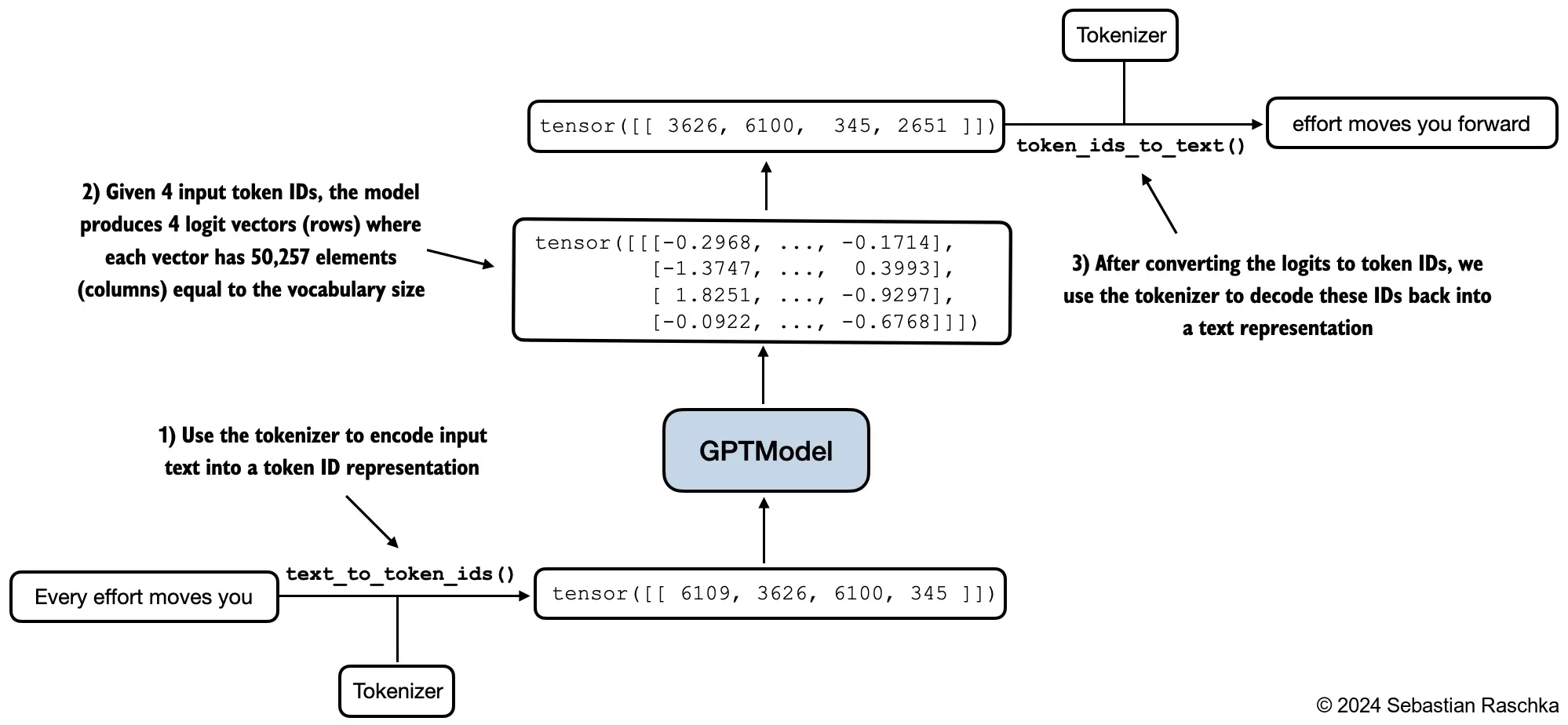
After pretraining, the model is often called a base model. It can complete text and may already show many useful emergent abilities, but it is not necessarily optimized for a specific downstream task or for assistant-like behavior.
Finetuning is a later stage where we continue training the pretrained model on a smaller, more specific dataset for a narrower purpose. In chapter 6 of the repo, the example is text classification finetuning for spam detection.
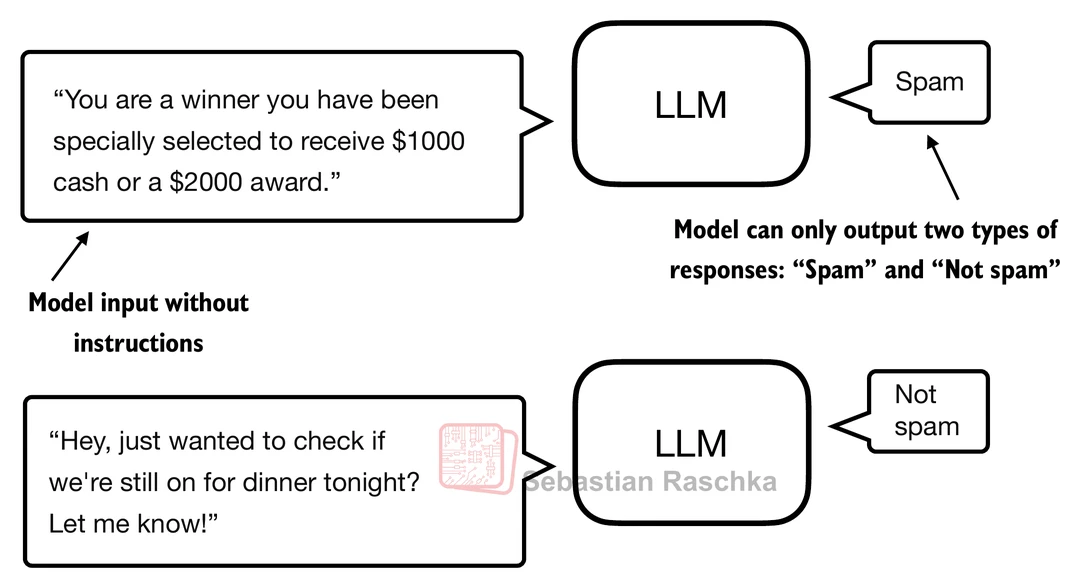
In that setup, the model is adapted for a task with a fixed label space such as "spam" versus "not spam". The goal is specialization. A classification-finetuned model is usually much narrower than a general assistant.
Instruction finetuning is a particular kind of finetuning aimed at making a base model follow prompts and respond in a more useful assistant-like way. Instead of training on class labels, the model is trained on prompt-response pairs.
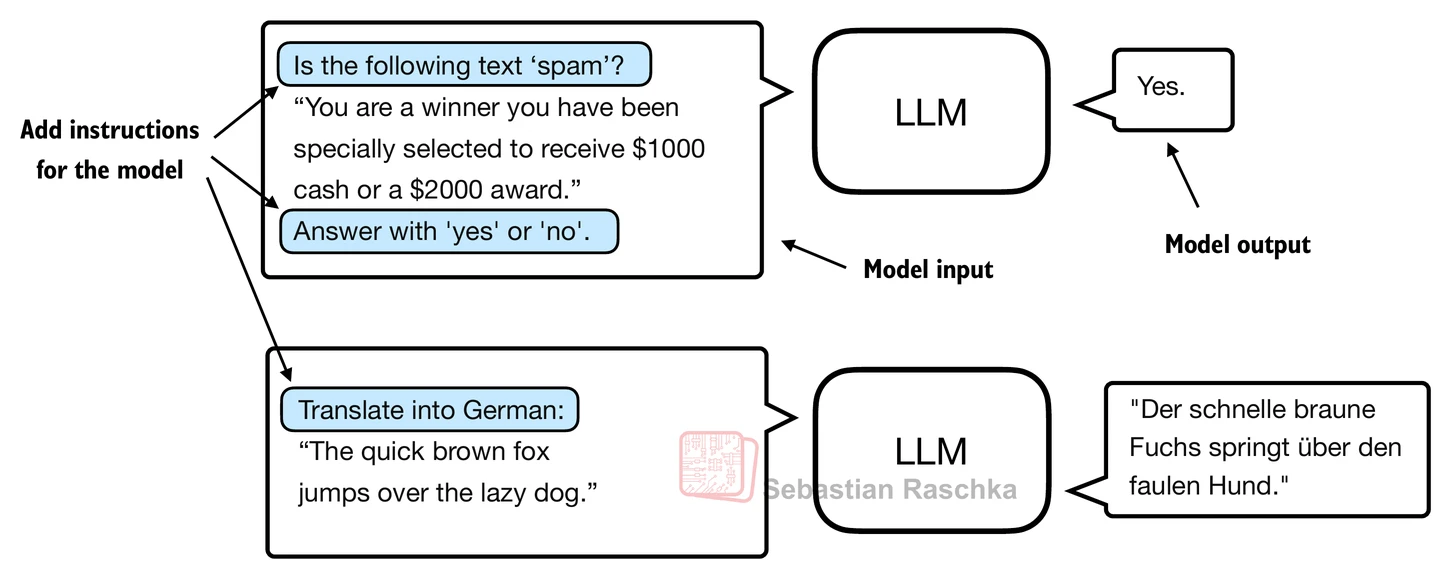
This difference matters in practice:
- Pretraining teaches the model how text tends to continue in general.
- Task finetuning teaches the model how to do one specific downstream task.
- Instruction finetuning teaches the model how to behave as a general prompt-following assistant across many tasks.
Another way to see it is by looking at the supervision source:
- Pretraining uses self-supervision from raw text.
- Finetuning usually uses labeled task data.
- Instruction finetuning uses curated prompt-response supervision.
The training objective also changes:
- Pretraining optimizes broad next-token prediction over a general corpus.
- Classification finetuning often changes the output head or loss to predict labels.
- Instruction finetuning usually keeps a generative next-token objective, but now the sequences are formatted as instructions plus desired responses.
This is why a base model and an instruct model can feel so different even when their core architecture is similar. The base model is optimized to continue text plausibly. The instruct model is optimized to continue it in a way that better satisfies the user’s request.
In short, pretraining builds the general language model, finetuning adapts it to a downstream task, and instruction finetuning is the special case of finetuning that turns a base model into a more useful prompt-following assistant.