What role does positional information play in a transformer-based LLM?
Positional information tells a transformer-based LLM where each token appears in the sequence. Without it, the model would know which tokens are present but not their order.
That matters because language is highly order-sensitive. The tokens in “dog bites man” are not interchangeable with the tokens in “man bites dog.” A transformer therefore needs some way to distinguish first, second, third, and later positions.
This is necessary because self-attention alone is permutation-invariant. If you gave attention the same set of token embeddings in a different order, and provided no positional signal, the attention mechanism itself would have no built-in notion of which token came earlier or later.
The repo illustrates this in chapter 2: a token embedding lookup gives the same vector for the same token ID regardless of where it appears in the sequence.

To fix this, the model adds positional information to the token representation before the transformer blocks process it.
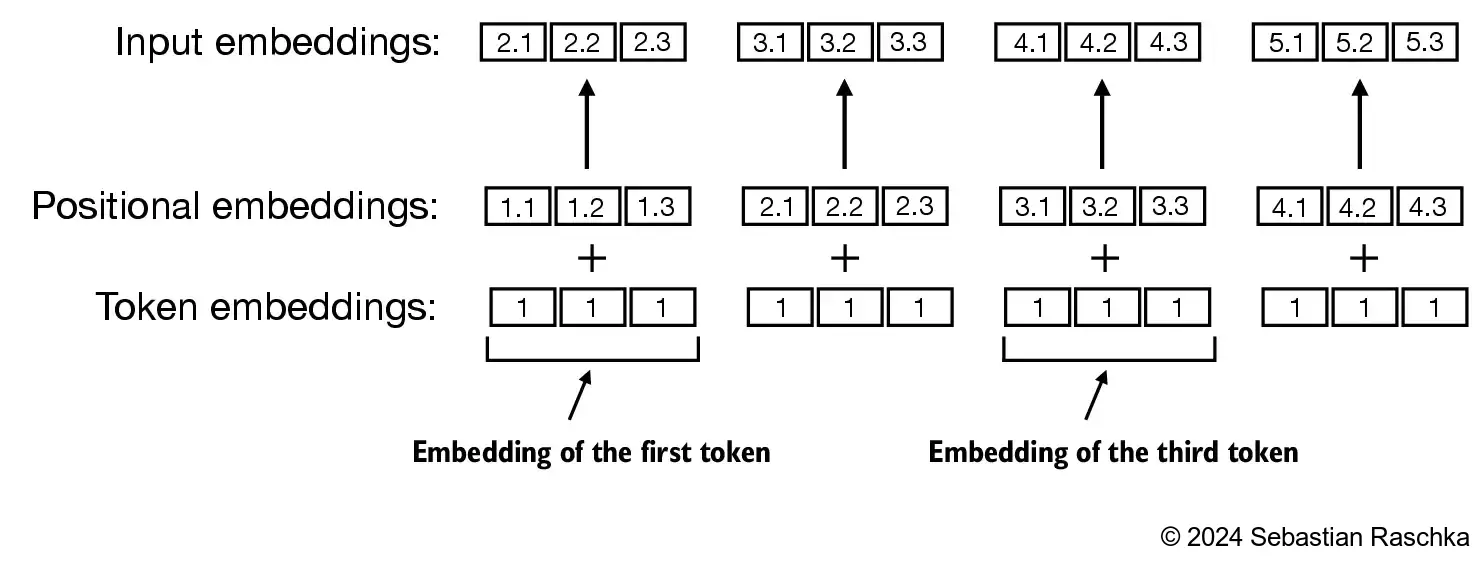
In the GPT-style model implemented in the repo, this is done with absolute positional embeddings. The model has:
- a token embedding table, which maps token IDs to vectors, and
- a positional embedding table, which maps position indices such as
0, 1, 2, ...to vectors.
These two vectors are added together, producing the input representation for each token position.
This positional signal plays several roles:
- It lets the model distinguish early from late tokens.
- It helps the model represent local order, such as which adjective modifies which noun.
- It helps the model interpret longer-range structure, such as sentence flow and discourse continuation.
- It effectively defines the model’s maximum context length when implemented with a fixed learned positional embedding table.
Modern architectures often encode position differently. For example, Llama-family models and many newer LLMs use rotary position embeddings (RoPE) inside attention rather than learned absolute position embeddings added at the input. But the purpose is the same: the model must know how token relationships depend on relative or absolute location.
So the exact implementation can change, but the need does not. A language model without positional information would struggle to represent order, and order is fundamental to syntax, semantics, and generation.
In short, positional information gives a transformer a sense of sequence order, which attention alone does not provide, and that is why every practical LLM includes some positional encoding mechanism.