Why do transformer-based LLMs use multi-head attention instead of a single attention mechanism?
Transformer-based LLMs use multi-head attention because a single attention mechanism is often too limited to capture all the different kinds of relationships that matter in language.
With just one attention head, the model produces one set of attention weights and one context vector per token. That can work, but it forces the model to compress many different interaction patterns into a single representation.
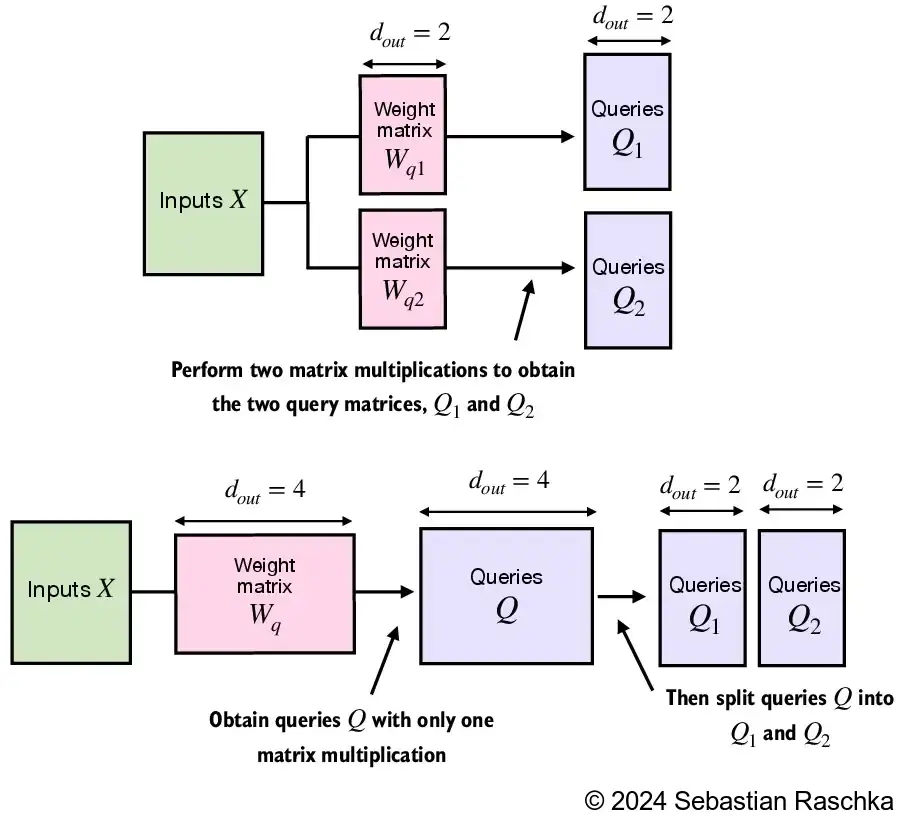
With multi-head attention, the model learns several separate attention heads in parallel. Each head has its own learned query, key, and value projections. So instead of producing one context view, the model produces several different context views and then combines them.
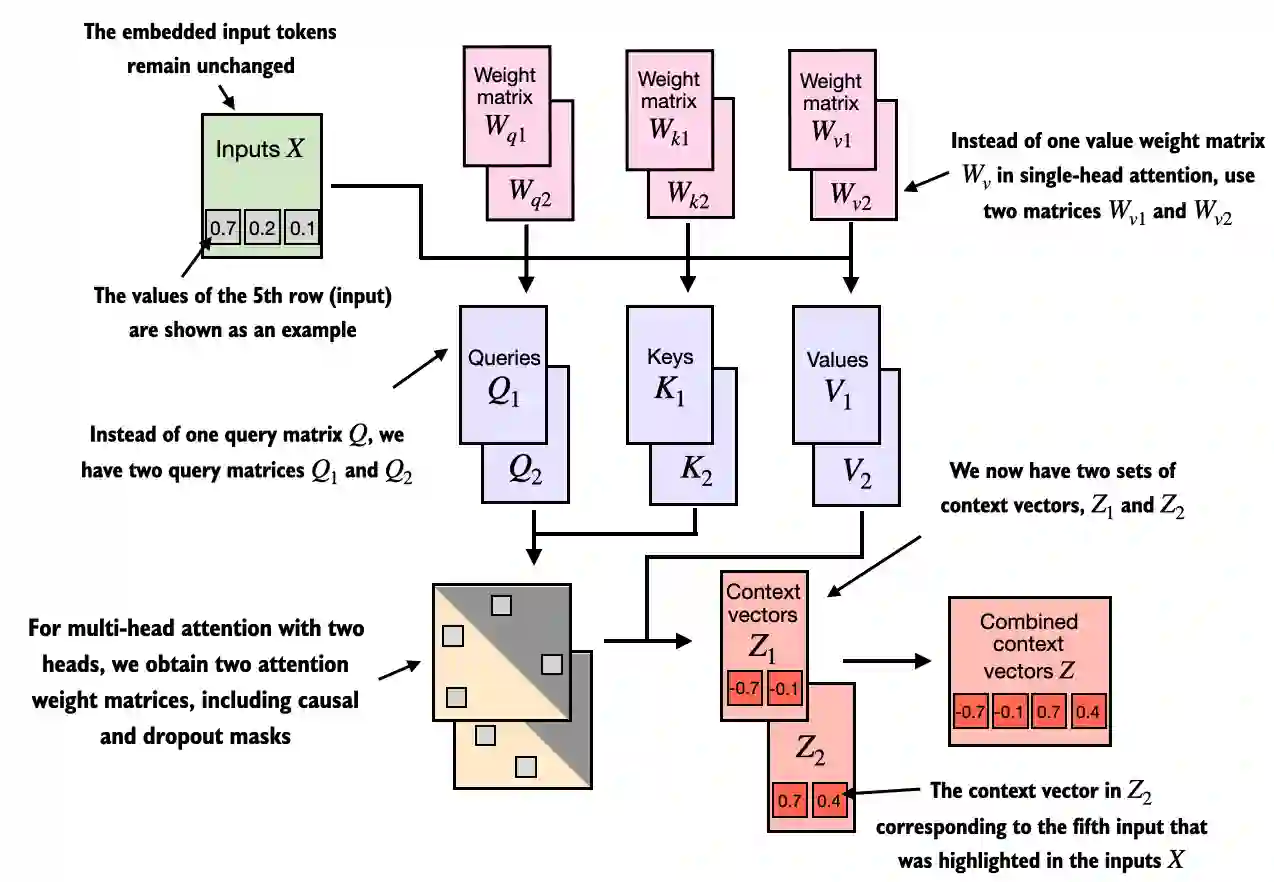
This helps for several reasons.
First, different heads can specialize in different kinds of dependencies. One head may focus on short-range grammatical structure, another on longer-range reference, another on list structure, and another on punctuation or formatting cues. The heads are not manually assigned these roles, but the architecture gives the model room to learn them.
Second, splitting attention into multiple heads lets the model operate in multiple learned subspaces. Rather than comparing tokens in one large projection space, each head gets its own smaller projection. This often makes it easier to learn diverse interactions.
Third, the outputs of the heads are concatenated and projected back into the model dimension, which gives the model a richer combined representation than a single attention summary would provide.
Conceptually, you can think of multi-head attention as asking the same question several different ways:
- Which earlier tokens matter for syntax?
- Which earlier tokens matter for meaning?
- Which earlier tokens matter for disambiguation?
- Which earlier tokens matter for current formatting or local continuation?
A single head can only produce one weighting pattern per token. Multi-head attention allows several weighting patterns at once.
This does not mean every head always learns something unique or equally useful. In large models, some heads can become redundant or more important than others. But overall, using multiple heads has proven to be a practical way to increase expressiveness while keeping the computation structured and scalable.
It is also worth noting that many newer architectures still keep the multi-head query idea even when they optimize the key and value side with methods such as grouped-query attention. That shows how central the multi-view design has become.
In short, transformers use multi-head attention instead of a single attention mechanism because multiple heads let the model learn different token relationships in parallel and combine them into a richer representation.