How do rank and alpha affect LoRA behavior in practice?
In LoRA, rank and alpha are the two most important adapter hyperparameters.
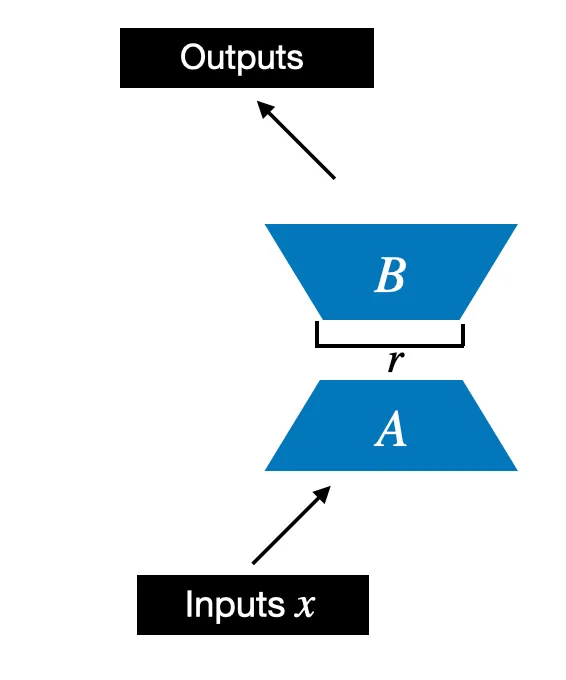
Rank controls the inner dimension of the low-rank update. In practical terms, it controls how much extra capacity the adapter has.
- lower rank means fewer trainable parameters and lower cost
- higher rank means more expressive adapters, but less parameter efficiency
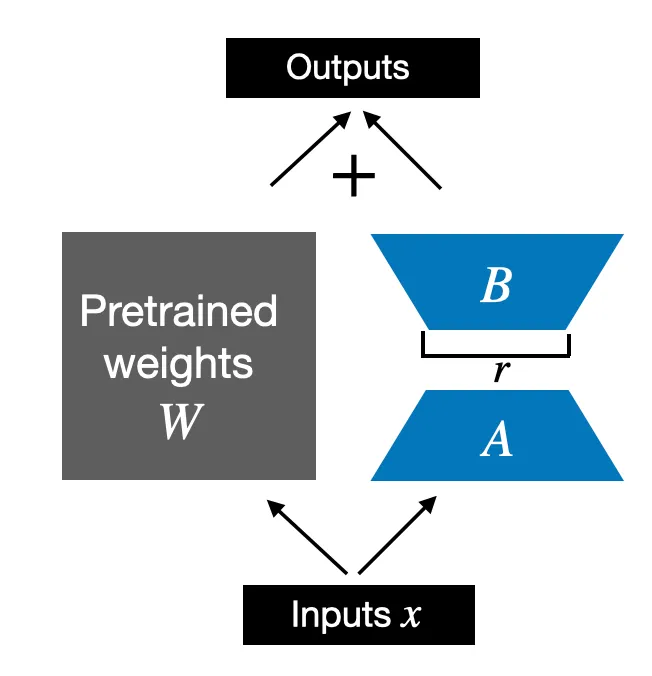
Alpha controls the scale of the LoRA update relative to the frozen base layer. In the repo code, the LoRA contribution is scaled by alpha / rank, which helps make runs across different ranks easier to compare without constantly retuning everything else.
That means alpha is not about capacity in the same way rank is. It is more about how strongly the adapter update influences the final layer output.
In practice:
- if rank is too low, the adapter may underfit
- if alpha is too low, the adapter may have too little effect
- if alpha is too high, the adapter can dominate too aggressively and training may become less well behaved
So rank and alpha work together:
- rank decides how much structure the adapter can learn
- alpha decides how much that learned structure changes the layer output
There is no single universally best pair. Smaller tasks and tighter hardware budgets often work with lower ranks, while harder adaptations may benefit from larger ranks and a well-chosen alpha.
In short, rank determines the capacity and size of a LoRA adapter, while alpha determines the strength of its contribution, and practical LoRA tuning is largely about choosing a good balance between those two.