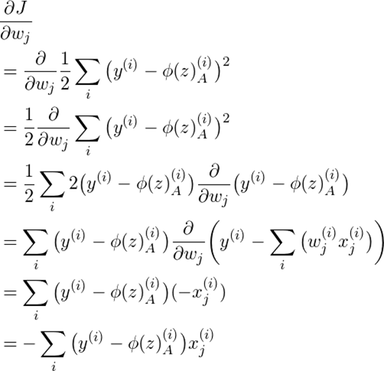How do you derive the gradient descent rule for linear regression and Adaline?
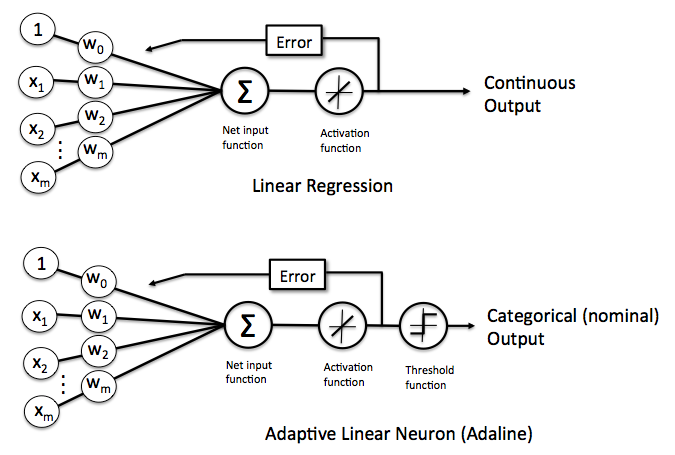
Linear Regression and Adaptive Linear Neurons (Adalines) are closely related to each other. In fact, the Adaline algorithm is a identical to linear regression except for a threshold function ![]() that converts the continuous output into a categorical class label
that converts the continuous output into a categorical class label
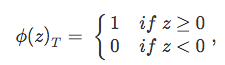
where $z$ is the net input, which is computed as the sum of the input features x multiplied by the model weights w:
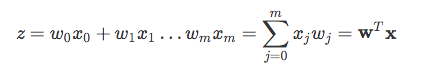
(Note that ![]() refers to the bias unit so that
refers to the bias unit so that ![]() .)
.)
In the case of linear regression and Adaline, the activation function ![]() is simply the identity function so that
is simply the identity function so that ![]() .
.
Now, in order to learn the optimal model weights w, we need to define a cost function that we can optimize. Here, our cost function ![]() is the sum of squared errors (SSE), which we multiply by
is the sum of squared errors (SSE), which we multiply by ![]() to make the derivation easier:
to make the derivation easier:
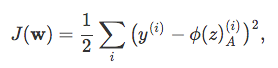
where ![]() is the label or target label of the ith training point
is the label or target label of the ith training point ![]() .
.
(Note that the SSE cost function is convex and therefore differentiable.)
In simple words, we can summarize the gradient descent learning as follows:
- Initialize the weights to 0 or small random numbers.
- For k epochs (passes over the training set)
- For each training sample
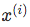
- Compute the predicted output value
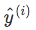
- Compare to the actual output
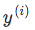 and Compute the “weight update” value
and Compute the “weight update” value - Update the “weight update” value
- Compute the predicted output value
- Update the weight coefficients by the accumulated “weight update” values
- For each training sample
Which we can translate into a more mathematical notation:
- Initialize the weights to 0 or small random numbers.
- For k epochs
- For each training sample
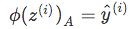
-
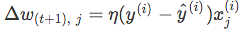 (where η is the learning rate);
(where η is the learning rate); 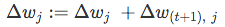
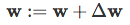
- For each training sample
Performing this global weight update
![]() ,
,
can be understood as “updating the model weights by taking an opposite step towards the cost gradient scaled by the learning rate η”
![]()
where the partial derivative with respect to each ![]() can be written as
can be written as
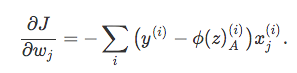
To summarize: in order to use gradient descent to learn the model coefficients, we simply update the weights w by taking a step into the opposite direction of the gradient for each pass over the training set – that’s basically it. But how do we get to the equation
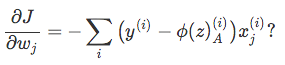
Let’s walk through the derivation step by step.