Why is inference sequential while training is much more parallel?
Training is much more parallel than inference because, during training, the model sees the whole input sequence and all next-token targets at once. During inference, it does not know the future tokens yet, so it has to generate them one by one.
In pretraining, the usual setup is teacher forcing: given a token sequence, the model predicts the next token at every position in parallel under a causal mask.

That makes training highly parallelizable across:
- positions within a sequence
- multiple sequences in a batch
- multiple devices
Inference is different. At generation time, the model must first choose token t+1 before it can use that new token to predict token t+2. That dependency chain makes generation inherently sequential across newly generated tokens.
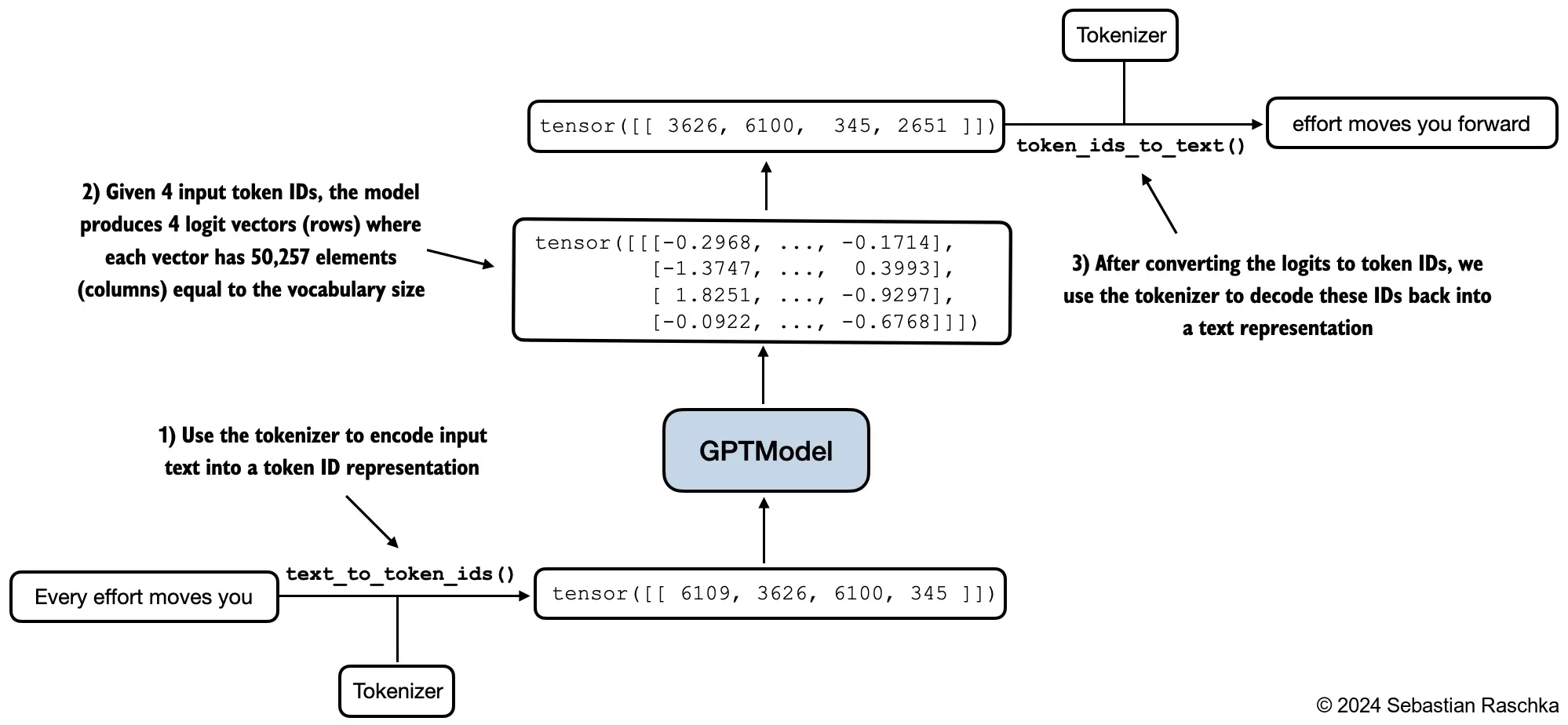
This is why LLM serving feels slower than training throughput might suggest. Training can compute many token predictions in parallel, but inference can only parallelize some parts of the work:
- across requests in a batch
- across prompt tokens during the initial prompt-processing stage
- across hardware kernels inside a single forward pass
But it still cannot escape the basic autoregressive rule: the next generated token must exist before the following one can be computed.
The KV cache helps by avoiding recomputation of past keys and values, but it does not remove this sequential dependency. It only makes each step cheaper.
In short, training is more parallel because the whole target sequence is already available and next-token predictions for many positions can be computed together, while inference is sequential because each new token must be generated before the model can use it to produce the next one.