How do architectures such as GPT, Llama, Qwen, and Gemma differ at a high level?
At a high level, GPT, Llama, Qwen, and Gemma all belong to the same broad family: they are transformer-based autoregressive language models. But they differ in several design choices that affect efficiency, scaling behavior, and deployment tradeoffs.
The easiest way to think about them is:
- GPT represents the earlier, simpler decoder-only transformer pattern.
- Llama is a modernized GPT-like family with more efficient building blocks.
- Qwen is another modern family that extends the Llama-style pattern with additional choices such as GQA, qk normalization, and MoE variants.
- Gemma is also a modern family, but with some distinctive choices around attention patterns and normalization layout.
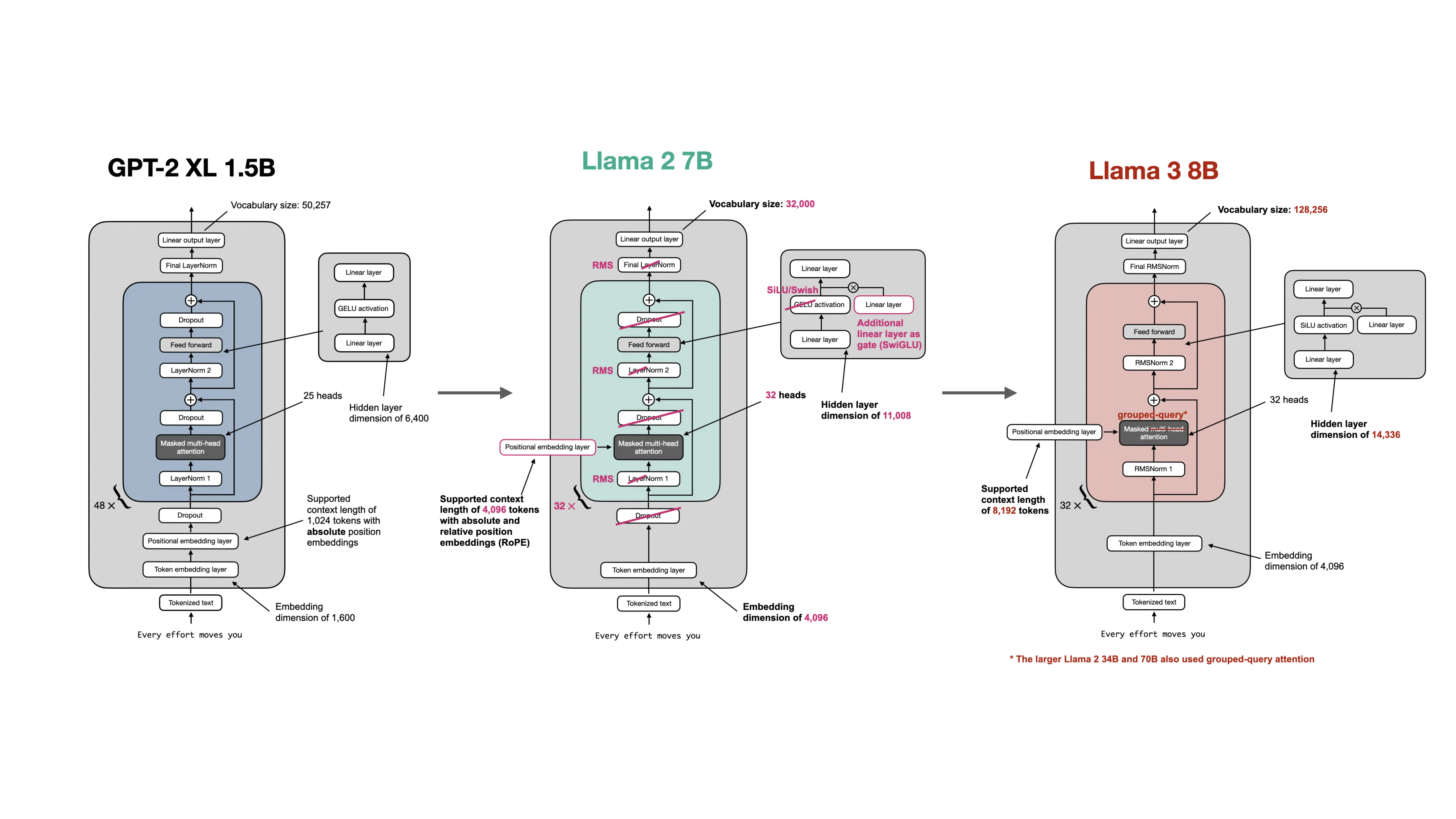
Here are the main differences in broad terms.
GPT-style models
- typically use learned absolute positional embeddings
- use LayerNorm
- use standard multi-head attention
- use a simpler feed-forward setup such as GELU MLP blocks
This is the clean educational baseline used in the early chapters of the repo.
Llama-family models
- replace LayerNorm with RMSNorm
- replace absolute positional embeddings with RoPE
- use bias-free linear layers
- use SwiGLU feed-forward blocks instead of the older GPT-style GELU block
- later variants use GQA for more efficient inference
These changes are meant to preserve strong performance while improving efficiency and scaling.
Qwen
- follows a modern RoPE + RMSNorm style architecture
- uses GQA
- includes additional details such as qk normalization
- comes in both dense and MoE variants in the repo
- often uses large vocabularies and product variants such as base, instruct, coder, and reasoning models

Gemma
- is also in the modern RoPE + RMSNorm family
- uses GQA
- includes different normalization placement details from simpler GPT/Llama baselines
- in Gemma 3, emphasizes efficiency-oriented attention design such as sliding-window attention mixed with global attention

So the most important point is not that these models come from completely different worlds. They are all descendants of the transformer decoder idea. The real differences are in architectural refinements such as:
- absolute versus rotary positional encoding
- LayerNorm versus RMSNorm
- standard MHA versus GQA
- GELU feed-forward blocks versus SwiGLU-style blocks
- full attention versus hybrids that include local or sliding-window attention
- dense versus sparse MoE variants
That is why modern architecture comparisons often feel incremental rather than revolutionary. Most of the time, the models share the same high-level blueprint and differ in how they optimize the details for scale, efficiency, and deployment.
In short, GPT is the simpler older decoder-only baseline, while Llama, Qwen, and Gemma are more modern transformer families that keep the same overall idea but make different choices about normalization, positional encoding, attention efficiency, and feed-forward design.