How can a pretrained LLM be finetuned for text classification?
A pretrained LLM can be finetuned for text classification by reusing its transformer backbone as a feature extractor and training a small task-specific classifier on top of it.
The repo’s chapter 6 uses spam classification as the running example. The basic idea is:
- Start with a pretrained GPT-style model.
- Replace the language-model output layer with a classification head.
- Feed labeled text examples through the model.
- Use one sequence representation, often the last token representation, as the summary for classification.
- Train with a classification loss such as cross-entropy.
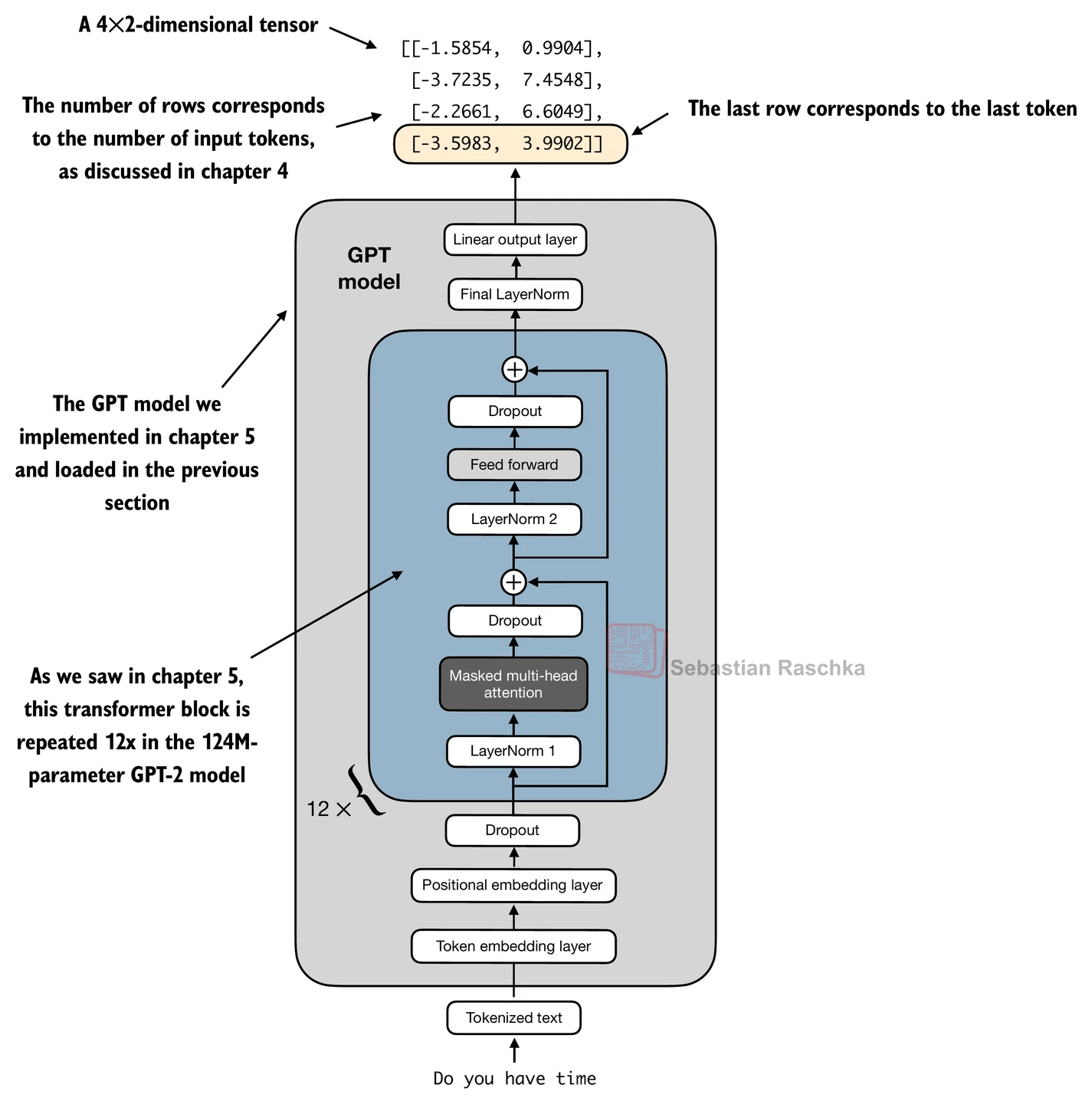
Why the last token? In a causal GPT-style model, later tokens can attend to more of the sequence than earlier ones. The final token representation therefore has access to the richest left-to-right summary of the input prefix.
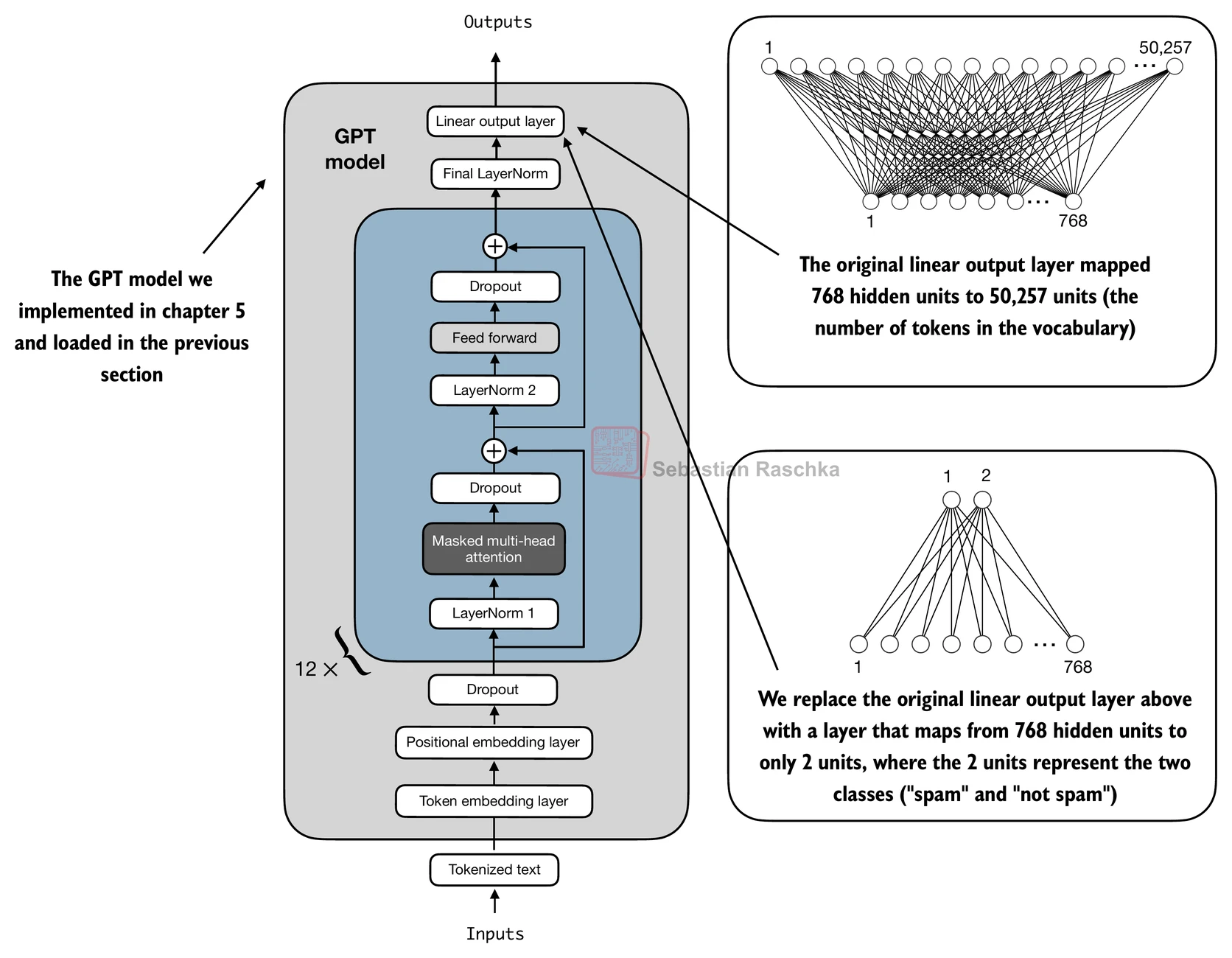
In chapter 6, the original vocabulary-sized output head is replaced by a small linear layer whose output dimension matches the number of classes. For binary spam detection, that means two output logits.
There are different choices for how many pretrained parameters to update:
- train only the new classification head
- train the head plus a few upper transformer layers
- finetune the full model
The repo uses a pragmatic middle ground by making the new head trainable and also unfreezing the last transformer block and the final normalization layer. This keeps the adaptation lightweight while still improving performance over training only the head.
Once the model outputs class logits, prediction is straightforward: apply argmax over the class dimension to pick the most likely class.

This setup differs from ordinary pretraining in an important way. During pretraining, the model predicts the next token for every position. During classification finetuning, the goal is no longer to generate the next token. The goal is to map the whole input text to one of a fixed number of labels.
That is why classification finetuning is much more specialized than instruction finetuning. A spam classifier can become very good at spam detection, but it will not turn into a general assistant from this process alone.
So the practical recipe is:
- load a pretrained LLM
- replace or adapt the output head for the number of classes
- choose a sequence summary representation, often the last token
- train on labeled task examples with classification loss
- optionally unfreeze some upper transformer layers for better adaptation
In short, a pretrained LLM can be finetuned for text classification by attaching a label-prediction head to the pretrained transformer, using its sequence representation as task features, and optimizing on labeled examples.