What is Direct Preference Optimization (DPO), and how does it differ from supervised finetuning?
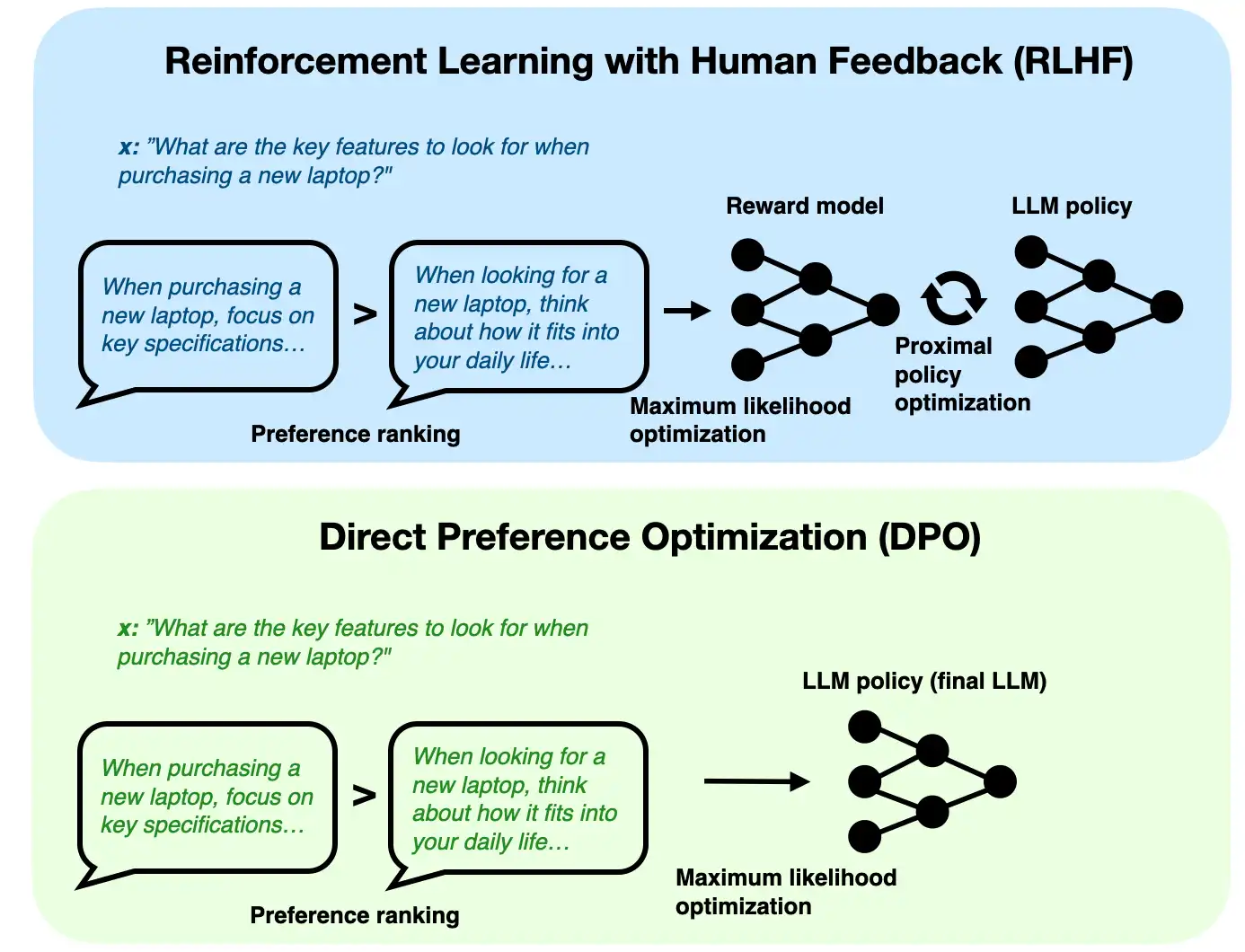
Direct Preference Optimization (DPO) is a preference-tuning method that trains an LLM from comparisons between a preferred response and a dispreferred response for the same prompt.
That makes it different from standard supervised finetuning (SFT), where the model is trained to imitate one target response directly.
In supervised finetuning, the training data looks like:
- prompt
- desired answer
The model simply learns to increase the likelihood of that answer.
In DPO, the training data instead looks like:
- prompt
- chosen response
- rejected response
The model is trained to score the chosen response higher than the rejected one, relative to a reference model.

This is useful because many prompts do not have exactly one correct continuation. There may be several acceptable answers, but some are more helpful, polite, concise, accurate, or better aligned with user preferences than others.
That is the motivation for preference tuning. The repo explains DPO as a simpler alternative to RLHF-style alignment. Traditional RLHF pipelines often require:
- an instruction-finetuned model
- a separate reward model
- a policy optimization stage
DPO tries to avoid that extra complexity by optimizing preferences more directly.
So the difference from supervised finetuning is not just the loss function. It is the type of supervision.
Supervised finetuning says:
“Here is the answer to imitate.”
DPO says:
“Given these two answers, prefer this one over that one.”
That makes DPO especially useful after instruction finetuning. A common workflow is:
- pretrain a base model
- instruction-finetune it with prompt-response pairs
- preference-tune it with DPO
This sequence makes sense because DPO assumes the model can already produce reasonably valid responses. It then nudges style and alignment by teaching relative preferences.
The chapter 7 DPO notebook in the repo also notes a practical caveat: DPO can be somewhat fragile. It often uses small learning rates and modest training runs because overdoing preference optimization can degrade generation quality.
In short, supervised finetuning teaches a model to imitate a target response, while DPO teaches it to prefer one response over another, making DPO a preference-alignment method rather than a plain imitation-learning method.