How do you compare supervised algorithms efficiency and accuracy-wise?
General comparisons between supervised algorithms are not trivial; there are lots of things to consider when comparing the predictive performance:
- Conducting fair hyperparameter tuning (e.g., use the same budget — number of hyperparameter values to consider — for all algorithms)
- Considering different & diverse datasets
- Using different performance metrics
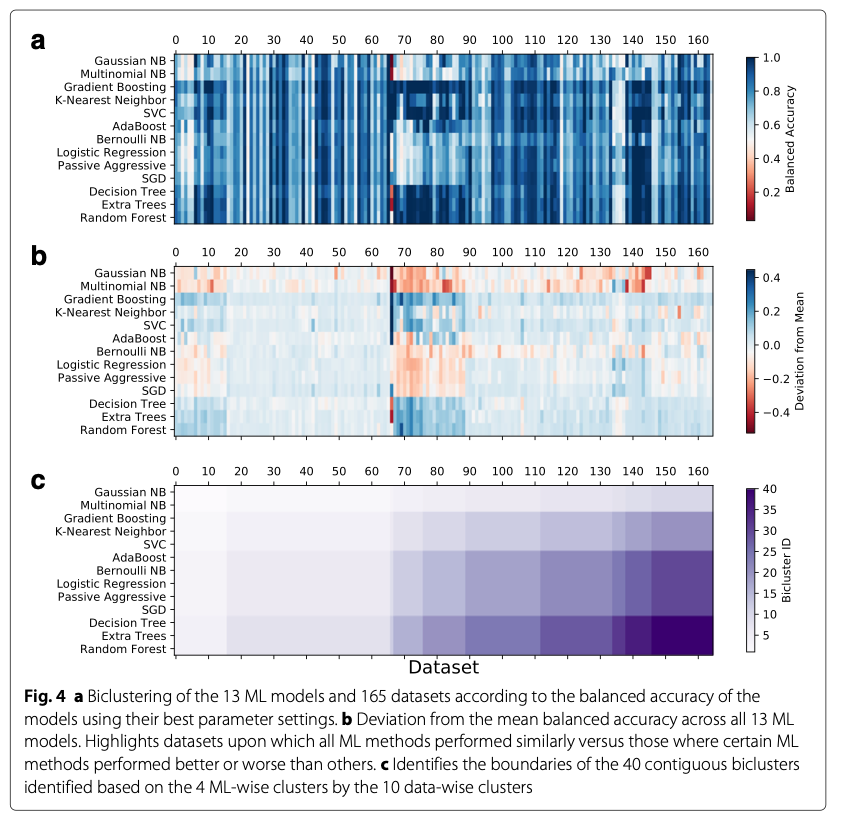
A good example of an relatively extensive study comparing supervised algorithms is the PMLB benchmark study from UPenn’s Epistasis Lab:
Olson, R. S., La Cava, W., Orzechowski, P., Urbanowicz, R. J., & Moore, J. H. (2017). PMLB: a large benchmark suite for machine learning evaluation and comparison. BioData mining, 10(1), 1-13.
Comparing computational efficiency can be done either theoretically or empirically. With theoretical comparison, I mean Big-O analysis:
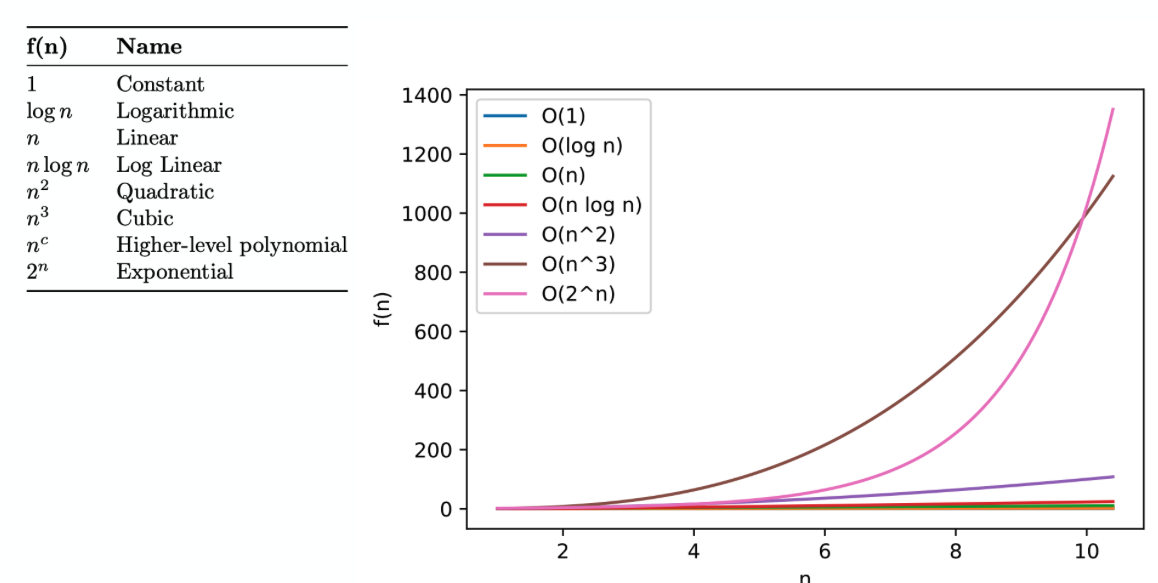
For example, a k-nearest neighbor algorithm in it’s naive implementation

Has O(k × n) run-time complexity (where N is the size of the training set) for during prediction. This can be improved to O(k log(n) using a priority queue data structure. On the other hand, (multinomial) logistic regression, the runtime is O((w+1) × c), where w is the number of weights (constant), and c is the number of classes (c=1 if we talk about regular, binary logistic regression). Based on this analysis, we can see that logistic regression should be more efficient than KNN as a function of the training examples for predicting the label (assuming large training sets, which are common in ML). If the dataset is small, KNN is probably fine.
Of course, you can do these comparisons computationally/empirically on different datasets (here, make sure you choose datasets with different numbers of features, training examples, test set examples, and classes).