Why do some LLMs remove bias terms from linear layers?
Some modern LLMs remove bias terms from linear layers because, in large transformer stacks, those biases often contribute less than the main weight matrices while still adding parameters, memory traffic, and implementation complexity.
In a standard linear layer, the output is a matrix multiplication plus a bias vector. Older transformer implementations often kept that bias term by default. But many newer Llama-style models set bias=False for most of the major linear projections.
Why is that reasonable?
- the transformer already has residual connections
- the model already has normalization layers
- most of the expressive power comes from the large learned weight matrices
So the bias can end up being a relatively small contribution compared with the rest of the block.
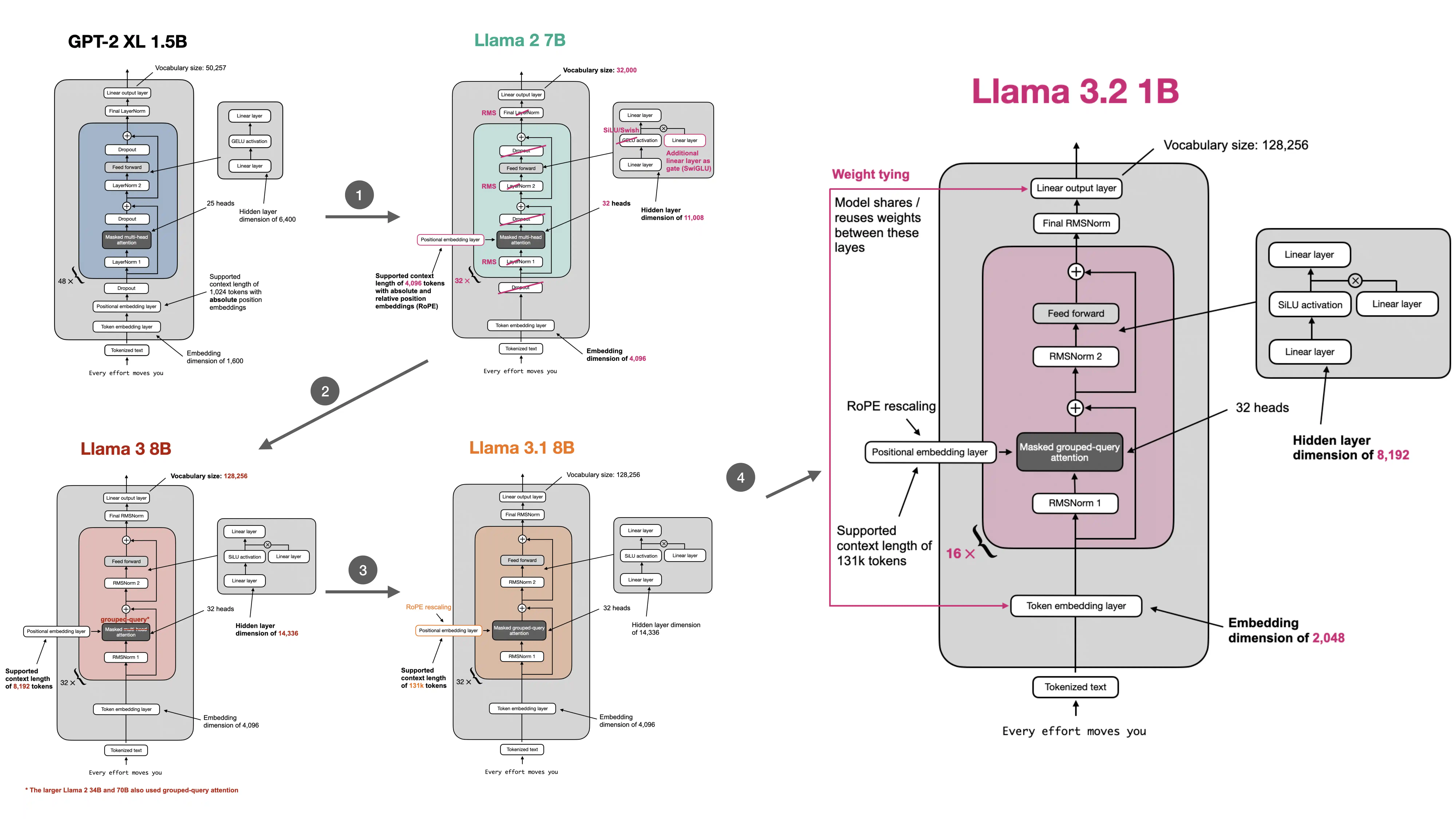
This is mostly an efficiency-minded cleanup, not a dramatic modeling breakthrough. Removing biases does not change the overall transformer idea. It just trims away a component that many modern implementations found less essential.
The design also fits the broader pattern in modern open-weight LLMs:
- use RMSNorm instead of LayerNorm
- use RoPE instead of learned absolute positional embeddings
- use SwiGLU instead of the older GPT-style feed-forward block
- remove bias terms where they do not seem necessary
All of these changes make the model feel a little more purposeful and streamlined.
It is also worth noting that this is not a universal law. Some models still keep biases in certain places. The point is not that bias terms are always harmful. The point is that large modern LLMs often found they could drop them with little downside.
In short, some LLMs remove bias terms from linear layers because those biases often provide only limited extra benefit once normalization and residual pathways are already doing most of the work, so removing them is a practical efficiency-oriented simplification.