How does batching affect LLM training speed and memory use?
Batching means processing multiple training sequences together in one step. For LLM training, it is one of the most important knobs for both speed and memory use.
Larger batches usually improve throughput because they let the GPU do more work per step and amortize overhead better.
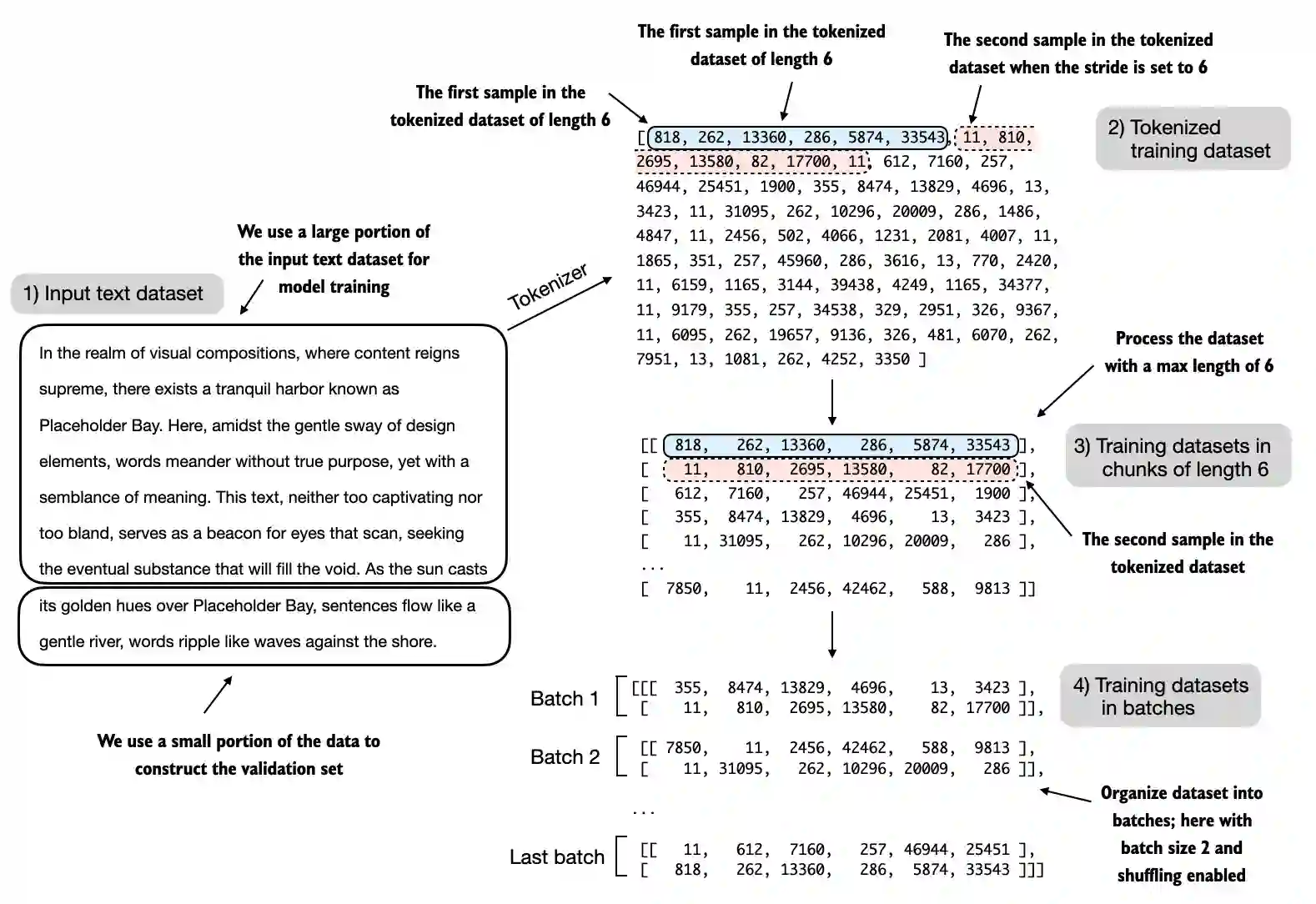
But batching is not free. As batch size grows, the model has to hold activations for more sequences at once, so memory usage rises. That means batch size competes directly with:
- context length
- model size
- precision choice
The repo’s training-speed material makes this tradeoff concrete. Increasing batch size was one of the final throughput optimizations, but it also pushed reserved memory back up substantially.
So the usual pattern is:
- small batch: easier to fit in memory, but worse hardware utilization
- larger batch: faster tokens per second, but higher memory demand

Another subtle point is optimization behavior. Very large effective batch sizes can change gradient noise and may require learning-rate retuning. So batching affects not only hardware efficiency but sometimes training dynamics as well.
When memory is tight, a common workaround is gradient accumulation. That keeps the per-step batch small enough to fit while simulating a larger effective batch over multiple mini-steps.
In short, larger batches usually speed up LLM training by improving hardware utilization, but they also raise memory usage, so batch size is always part of a tradeoff with context length, model size, and training stability.