First Look at Reasoning From Scratch: Chapter 1
Hi everyone,
As you know, I’ve been writing a lot lately about the latest research on reasoning in LLMs. Before my next research-focused blog post, I wanted to offer something special to my paid subscribers as a thank-you for your ongoing support.
So, I’ve started writing a new book on how reasoning works in LLMs, and here I’m sharing the first Chapter 1 with you. This ~15-page chapter is an introduction reasoning in the context of LLMs and provides an overview of methods like inference-time scaling and reinforcement learning.
Thanks for your support! I hope you enjoy the chapter, and stay tuned for my next blog post on reasoning research!
Happy reading,
Sebastian
Chapter 1: Introduction
Welcome to the next stage of large language models (LLMs): reasoning. LLMs have transformed how we process and generate text, but their success has been largely driven by statistical pattern recognition. However, new advances in reasoning methodologies now enable LLMs to tackle more complex tasks, such as solving logical puzzles or multi-step arithmetic. Understanding these methodologies is the central focus of this book.
In this introductory chapter, you will learn:
- What “reasoning” means specifically in the context of LLMs.
- How reasoning differs fundamentally from pattern matching.
- The conventional pre-training and post-training stages of LLMs.
- Key approaches to improving reasoning abilities in LLMs.
- Why building reasoning models from scratch can improve our understanding of their strengths, limitations, and practical trade-offs.
After building foundational concepts in this chapter, the following chapters shift toward practical, hands-on coding examples to directly implement reasoning techniques for LLMs.
1.1 What Does “Reasoning” Mean for Large Language Models?
What is LLM-based reasoning? The answer and discussion of this question itself would provide enough content to fill a book. However, this would be a different kind of book than this practical, hands-on coding focused book that implements LLM reasoning methods from scratch rather than arguing about reasoning on a conceptual level. Nonetheless, I think it’s important to briefly define what we mean by reasoning in the context of LLMs.
So, before we transition to the coding portions of this book in the upcoming chapters, I want to kick off this book with this section that defines reasoning in the context of LLMs, and how it relates to pattern matching and logical reasoning. This will lay the groundwork for further discussions on how LLMs are currently’ built, how they handle reasoning tasks, and what they are good and not so good at.
This book’s definition of reasoning, in the context of LLMs, goes as follows:
Reasoning, in the context of LLMs, refers to the model’s ability to produce intermediate steps before providing a final answer. This is a process that is often described as chain-of-thought (CoT) reasoning. In CoT reasoning, the LLM explicitly generates a structured sequence of statements or computations that illustrate how it arrives at its conclusion.
Figure 1.1 illustrates a simple example of multi-step (CoT) reasoning in an LLM.
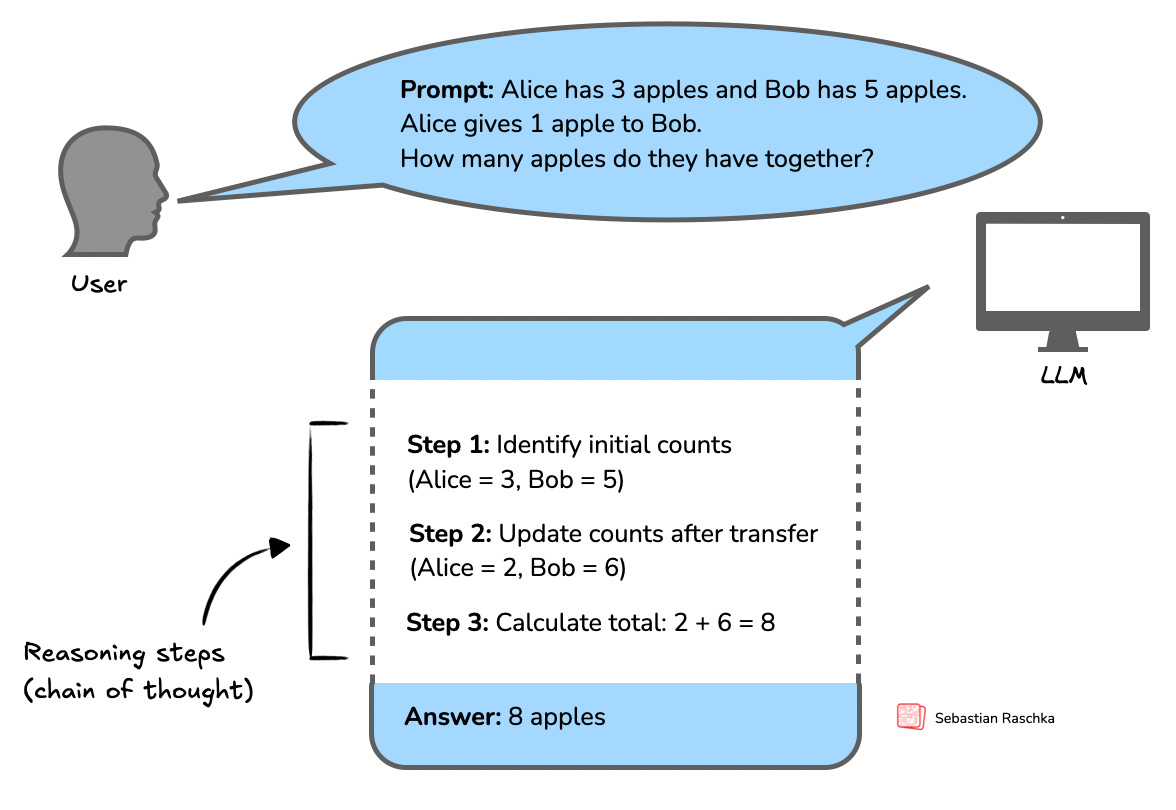
LLM-produced intermediate reasoning steps, as shown in Figure 1.1, look very much like a person is articulating internal thoughts aloud. Yet how closely these methods (and the resulting reasoning processes) mirror human reasoning remains an open question, one this book does not attempt to answer. It’s not even clear that such a question can be definitively answered.
Instead, this book focuses on explaining and implementing the techniques that improve LLM-based reasoning and make these models better at handling complex tasks. My hope is that by gaining hands-on experience with these methods, you will be better prepared to understand and improve those reasoning methods being developed and maybe even explore how they compare to human reasoning.
Note: Reasoning processes in LLMs may closely resemble human thought, particularly in how intermediate steps are articulated. However, it’s not (yet) clear whether LLM reasoning mirrors human reasoning in terms of internal cognitive processes. Humans often reason by consciously manipulating concepts, intuitively understanding abstract relationships, or generalizing from few examples. In contrast, current LLM reasoning is primarily based on patterns learned from extensive statistical associations present in training data, rather than explicit internal cognitive structures or conscious reflection.
Thus, although the outputs of reasoning-enhanced LLMs can appear human-like, the underlying mechanisms (likely) differ substantially and remain an active area of exploration.
1.2 A Quick Refresher on LLM Training
This section briefly summarizes how LLMs are typically trained so that we can better appreciate their design and understand where their limitations lie. This background will also help frame our upcoming discussions on the differences between pattern matching and logical reasoning.
Before applying any specific reasoning methodology, traditional LLM training is usually structured into two stages: pre-training and post-training, which are illustrated in Figure 1.2 below.
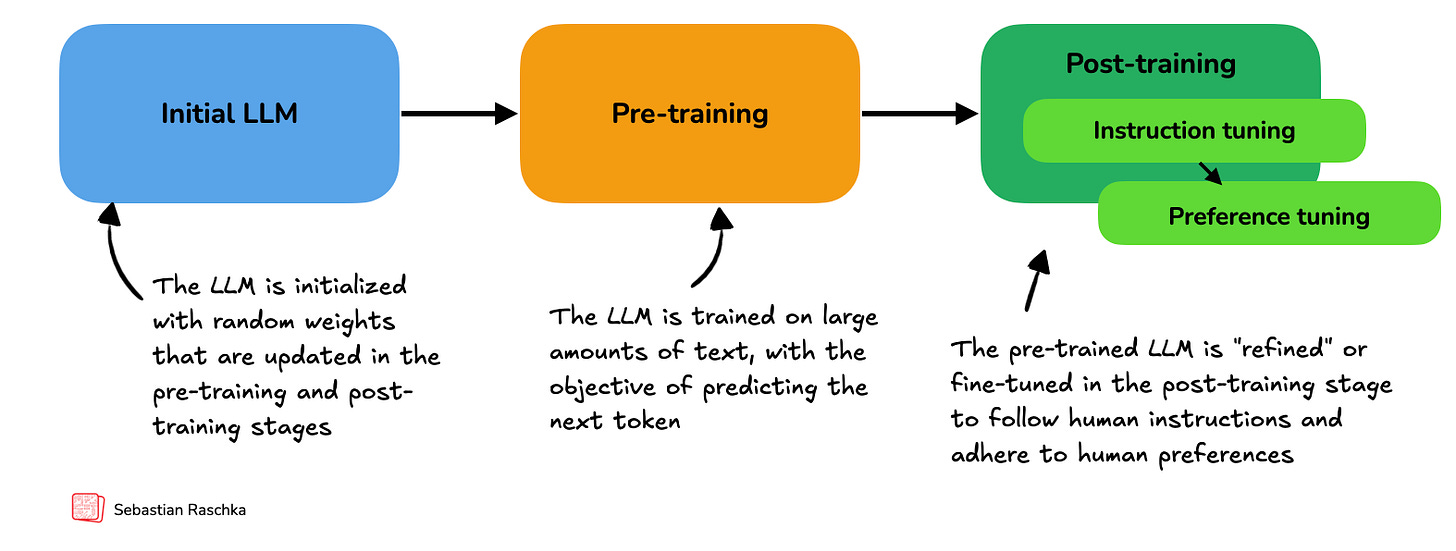
In the pre-training stage, LLMs are trained on massive amounts (many terabytes) of unlabeled text, which includes books, websites, research articles, and many other sources. The pre-training objective for the LLM is to learn to predict the next word (or token) in these texts.
When pre-trained on a massive scale, on terabytes of text, which requires thousands of GPUs running for many months and costs millions of dollars for leading LLMs, the LLMs become very capable. This means they begin to generate text that closely resembles human writing. Also, to some extent, pre-trained LLMs will begin to exhibit so-called emergent properties, which means that they will be able to perform tasks that they were not explicitly trained to do, including translation, code generation, and so on.
However, these pre-trained models merely serve as base models for the post-training stage, which uses two key techniques: supervised fine-tuning (SFT, also known as instruction tuning) and preference tuning to teach LLMs to respond to user queries, which are illustrated in Figure 1.3 below.
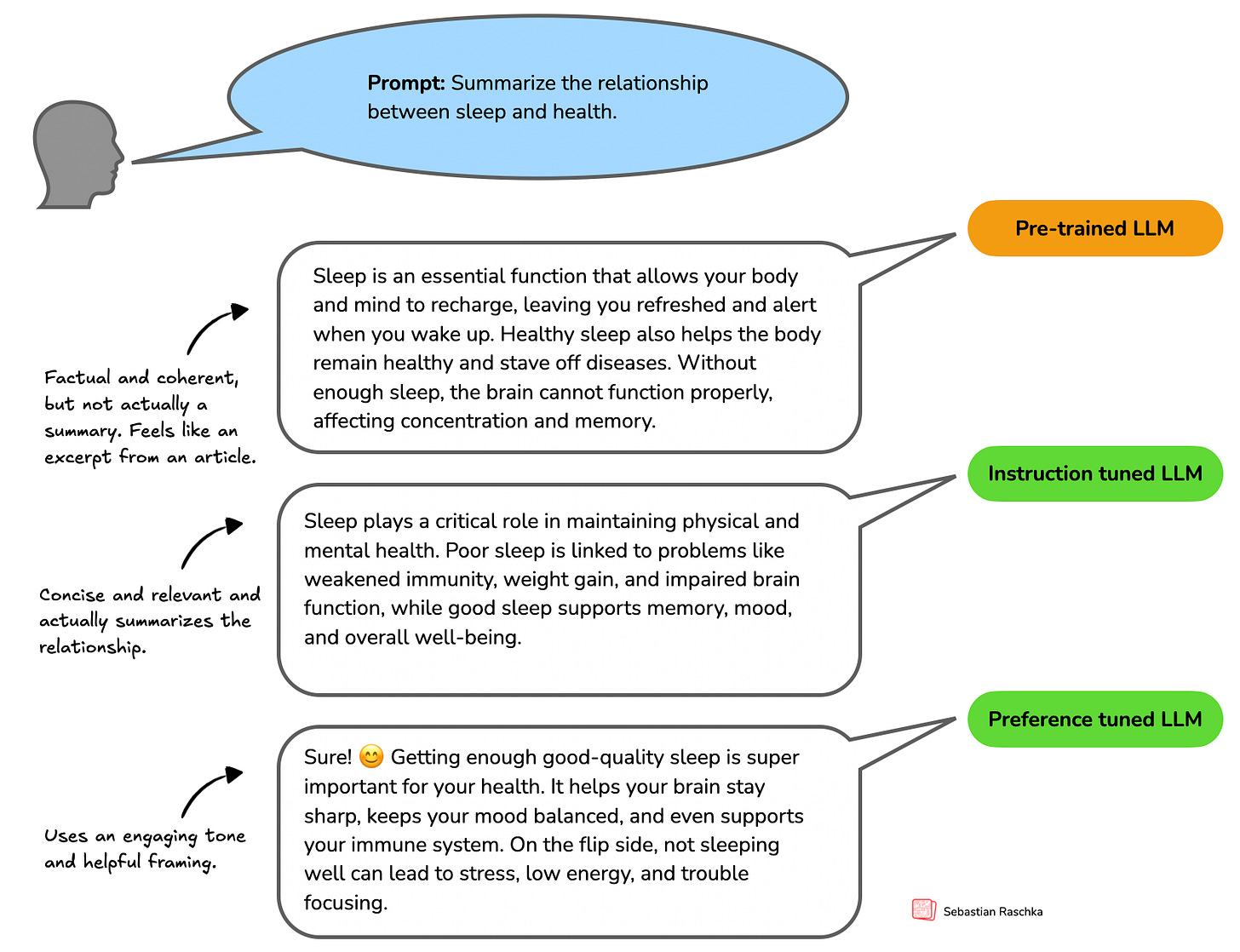
As shown in Figure 1.3, instruction tuning improves an LLM’s capabilities of personal assistance-like tasks like question-answering, summarizing and translating text, and many more. The preferences tuning stage then refines these capabilities. It helps tailor responses to user preferences. In addition, preference tuning is also used to make LLMs safer. (Some readers may be familiar with terms like Reinforcement Learning Human Feedback or RLHF, which are specific techniques to implement preference tuning.)
In short, we can think of pre-training as “raw language prediction” (via next-token prediction) that gives the LLM some basic properties and capabilities to produce coherent texts. The post-training stage then improves the task understanding of LLMs via instruction tuning and refines the LLM to create answers with preferred stylistic choices via preference tuning.
These pre-training and post-training stages mentioned above are covered in my book “Build A Large Language Model (From Scratch).” The book you are reading now does not require detailed knowledge of these stages. We will start with a model that has undergone pre-training an post-training. Concretely, we implement the architecture of the Initial LLM in Chapter 2 and load openly available weights of a model that has undergone the expensive pre-training and post-training stages mentioned above. After evaluating the base model, the subsequent chapters in this book will then implement and apply reasoning methods on top.
1.3 Pattern Matching: How LLMs Learn from Data
As mentioned in the previous section, during pre-training, LLMs are exposed to vast quantities of text and learn to predict the next token by identifying and reproducing statistical associations…
You are reading a free excerpt from a subscriber-only article.
The full article is available in my
Ahead of AI magazine.
Subscribing supports independent AI research and writing.