Influential Machine Learning Papers Of 2022
Happy New Year!
It’s been ten years since I first started exploring the field of machine learning, but this year has proven to be the most exciting and eventful one yet. Every day brings something new and exciting to the world of machine learning and AI, from the latest developments and breakthroughs in the field to emerging trends and challenges.
To mark the start of the new year, below is a short review of the top ten papers I’ve read in 2022.
Three Papers of the Year
The following are the top three papers that I read in 2022, along with a short discussion of each. Of course, there are many, many more exciting and potentially timeless and influential papers that were published this year.
Keeping it to “only” top-3 was particularly challenging this year, so there is also an extended list below featuring seven additional papers from my top-10 list.
1) ConvNeXt
The A ConvNet for the 2020s paper is a highlight for me because the authors were able to design a purely convolutional architecture that outperformed popular vision transformers such as Swin Transformer (and all convolutional neural networks that came before it, of course).
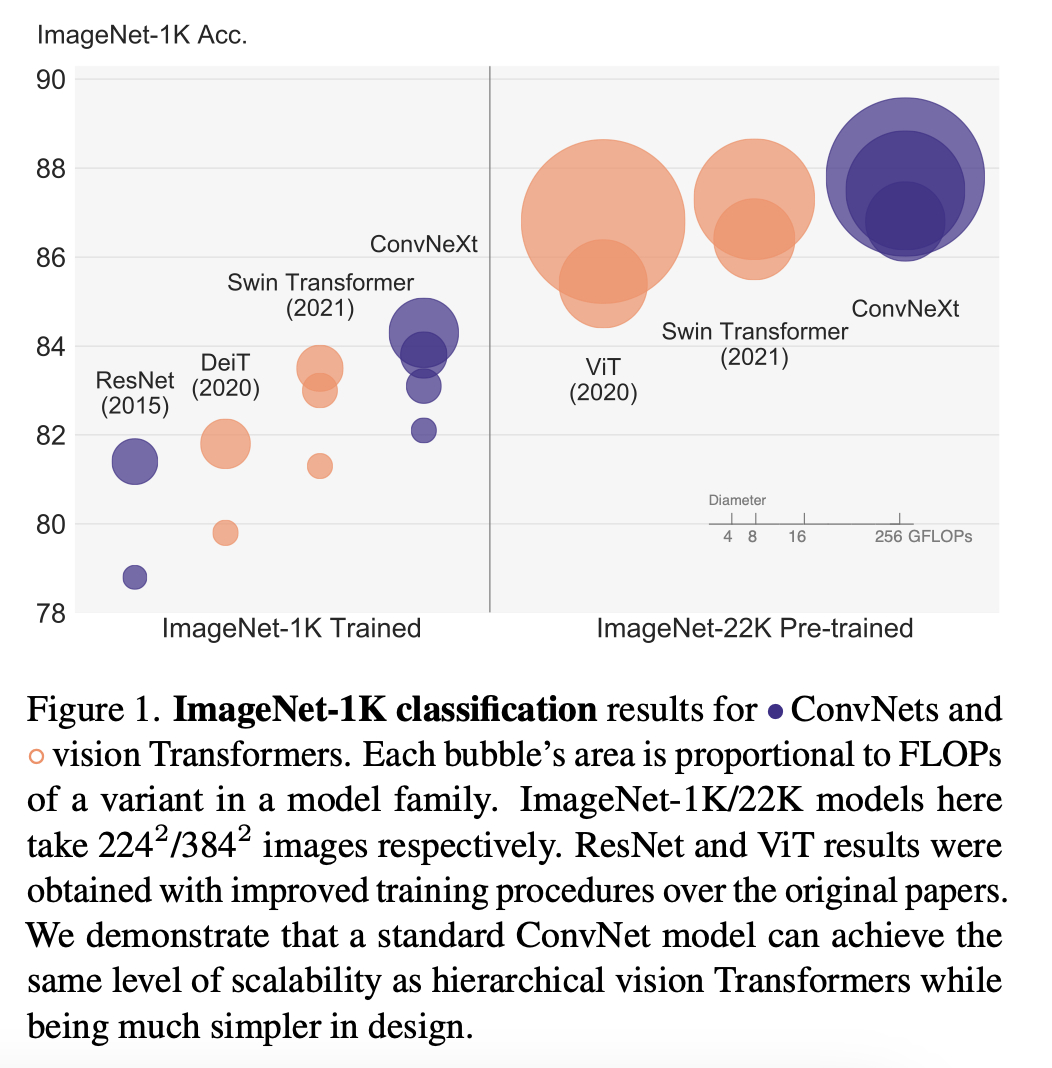
(Source: https://arxiv.org/abs/2201.03545)
This so-called ConvNeXt architecture may well be the new default when it comes to using convolutional neural networks not only for classification, but also object detection and instance segmentation – it can be used as a backbone for Mask R-CNN, for example.
As the authors stated in the paper, they were inspired by modern vision transformer training regimes as well as the fact that the Swin Transformer hybrid architecture showed that convolutional layers are still relevant. That’s because pure vision transformer architectures lack useful inductive biases such as translation equivariance and parameter-sharing (i.e., the “sliding window” in convolutions).
To develop ConvNeXt, the authors started out with a ResNet-50 base architecture and adopted architecture modifications and training regimes adopted from modern vision transformer training regimes. Note that these were not new, even in the context of convolutional neural networks. However, the novelty here is that the authors used, analyzed, and combined these techniques effectively.
Which techniques did they adopt? It’s a long list, including depthwise convolutions, inverted bottleneck layer designs, AdamW, LayerNorm, and many more. You can find a summary in the figure below. In addition, the authors also used modern data augmentation techniques such as Mixup, Cutmix, and others.
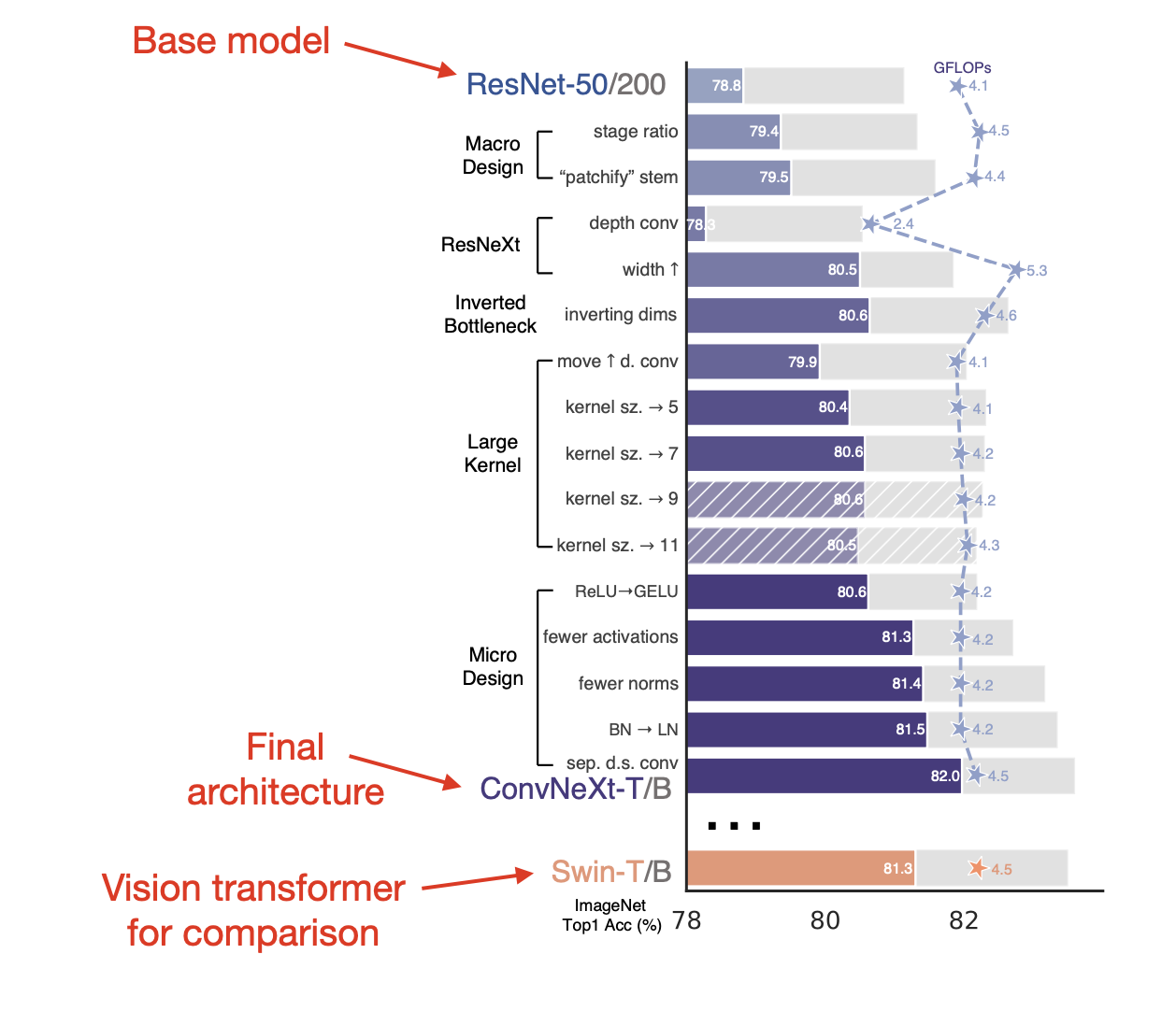
(Annotated version of a figure from https://arxiv.org/abs/2201.03545)
2) MaxViT
Despite convolutional neural networks making quite the comeback with ConvNeXt above, vision transformers are currently getting all the attention (no pun intended).
MaxViT: Multi-axis Vision Transformer highlights how far vision transformers have come in recent years. While early vision transformers suffered from quadratic complexity, many tricks have been implemented to apply vision transformers to larger images with linear scaling complexity.
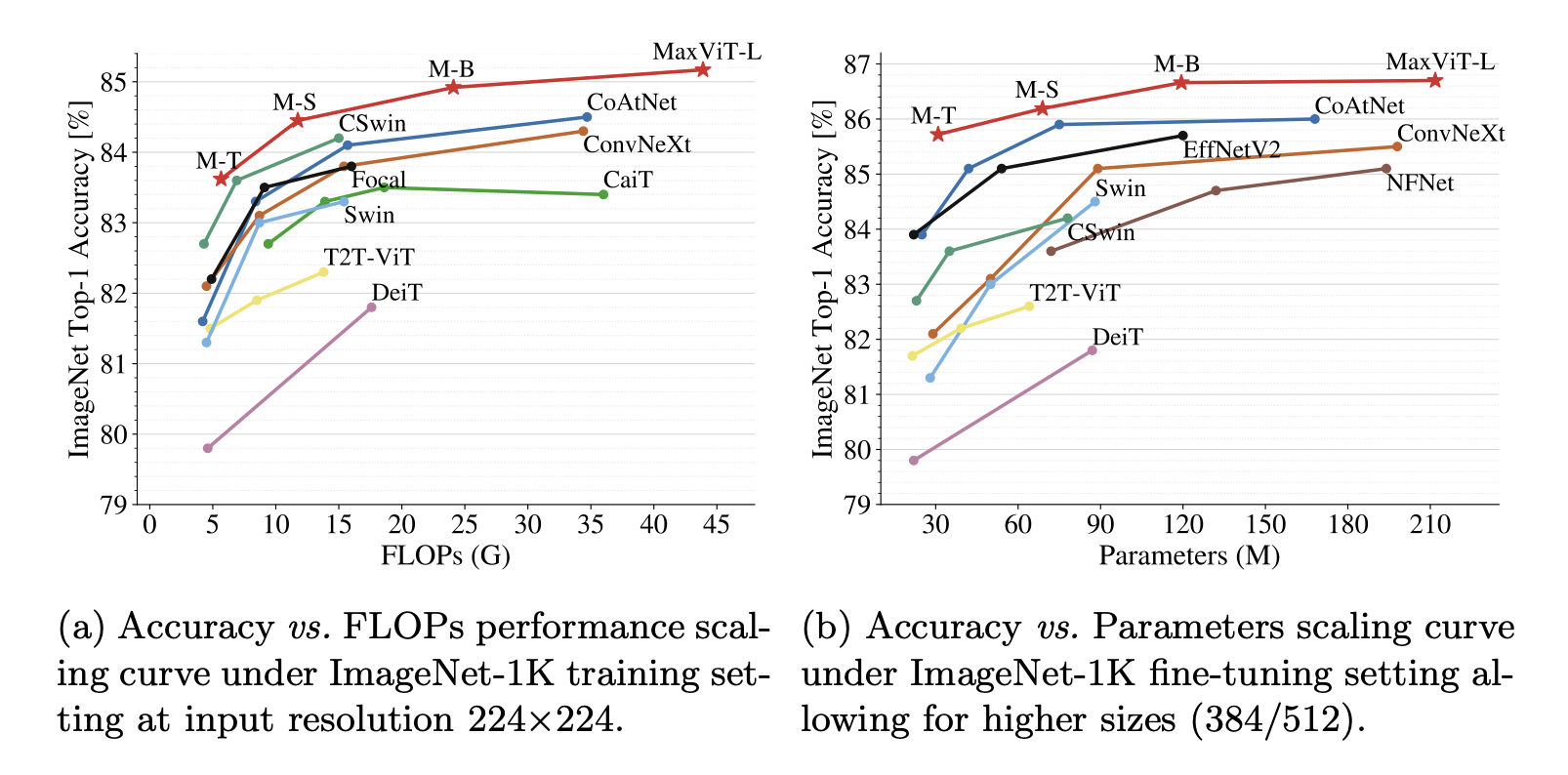
(Source: https://arxiv.org/abs/2204.01697)
Title: Released in September, MaxViT is currently state-of-the-art on ImageNet benchmarks.
In MaxViT, this is achieved by decomposing an attention block into two parts with local-global interaction:
- local attention (“block attention”);
- global attention (“grid attention”).
It’s worth mentioning that MaxViT is a convolutional transformer hybrid featuring convolutional layers as well.
And it can be used for predictive modeling (incl. classification, object detection, and instance segmentation) as well as generative modeling.
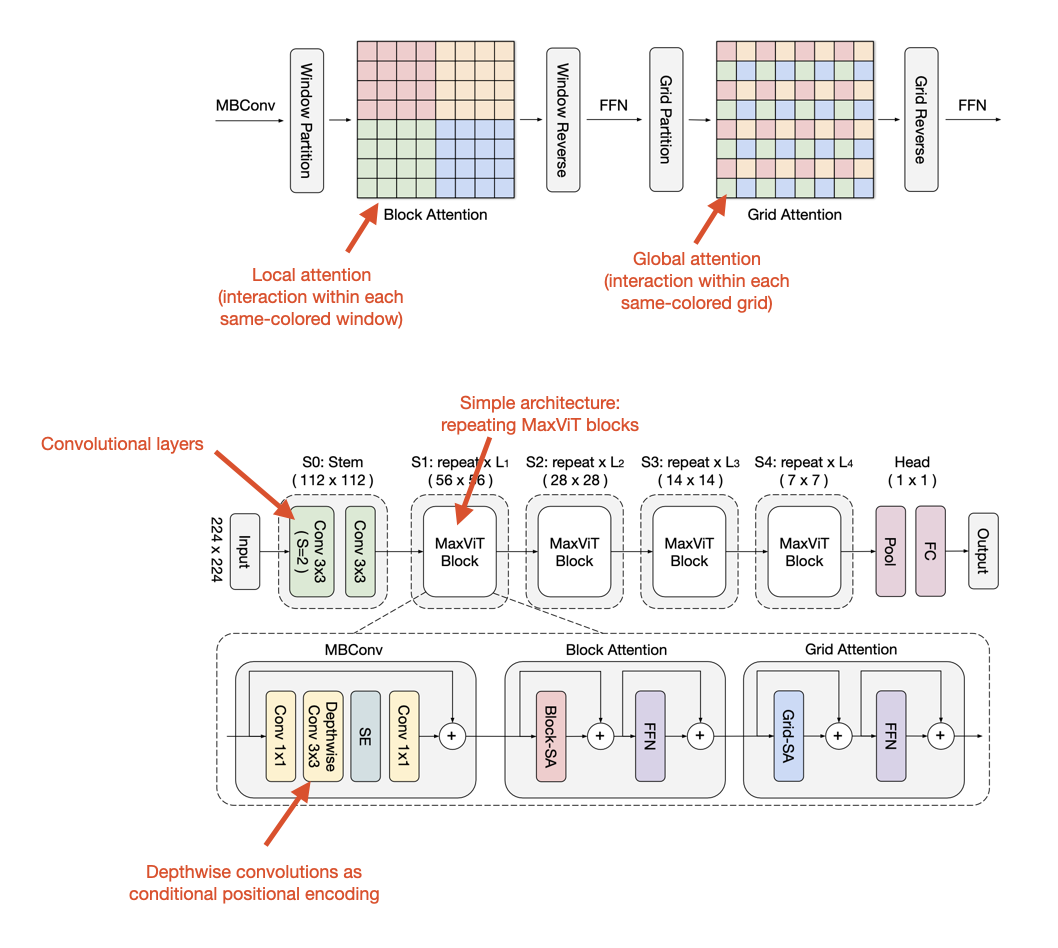
(Annotated version of a figure from https://arxiv.org/abs/2204.01697)
As a side note, a search for “vision transformer” on Google Scholar yields over 5,000 results for 2022 alone. This high number of results, while potentially including false positives, demonstrates the widespread popularity and interest in vision transformers.
But no worries, vision transformers won’t entirely replace our beloved convolutional neural networks. Instead, as MaxViT highlights, the current trend goes towards combining vision transformers and convolutional networks into hybrid architectures.
3) Stable Diffusion
Before ChatGPT became the state of the show, it was not too long ago since Stable Diffusion was all over the internet and social media. Stable Diffusion is based on the paper High-Resolution Image Synthesis with Latent Diffusion Models, which was uploaded in December 2021. But since it was presented at CVPR 2022 and got the spotlight with the Stable Diffusion in August 2022, I think it’s fair to include it in this 2022 list.
Diffusion models (the topic of the first Ahead of AI issue), are a type of probabilistic model that are designed to learn the distribution of a dataset by gradually denoising a normally distributed variable. This process corresponds to learning the reverse process of a fixed Markov Chain over a length of T.

(Illustration of a diffusion model)
Unlike GANs, which are trained using a minimax game between a generator and a discriminator, diffusion models are likelihood-based models trained using maximum likelihood estimation (MLE). This can help to avoid mode collapse and other training instabilities.
Diffusion models have been around for some time (see Deep Unsupervised Learning using Nonequilibrium Thermodynamics, 2015) but were notoriously expensive to sample from during training and inference. The authors of the 2022 paper above mentioned a runtime of 5 days to sample 50k images.
The High-Resolution Image Synthesis with Latent Diffusion Models paper’s novelty is in applying diffusion in latent space using pretrained autoencoders instead of using the full-resolution raw pixel input space of the original images directly.
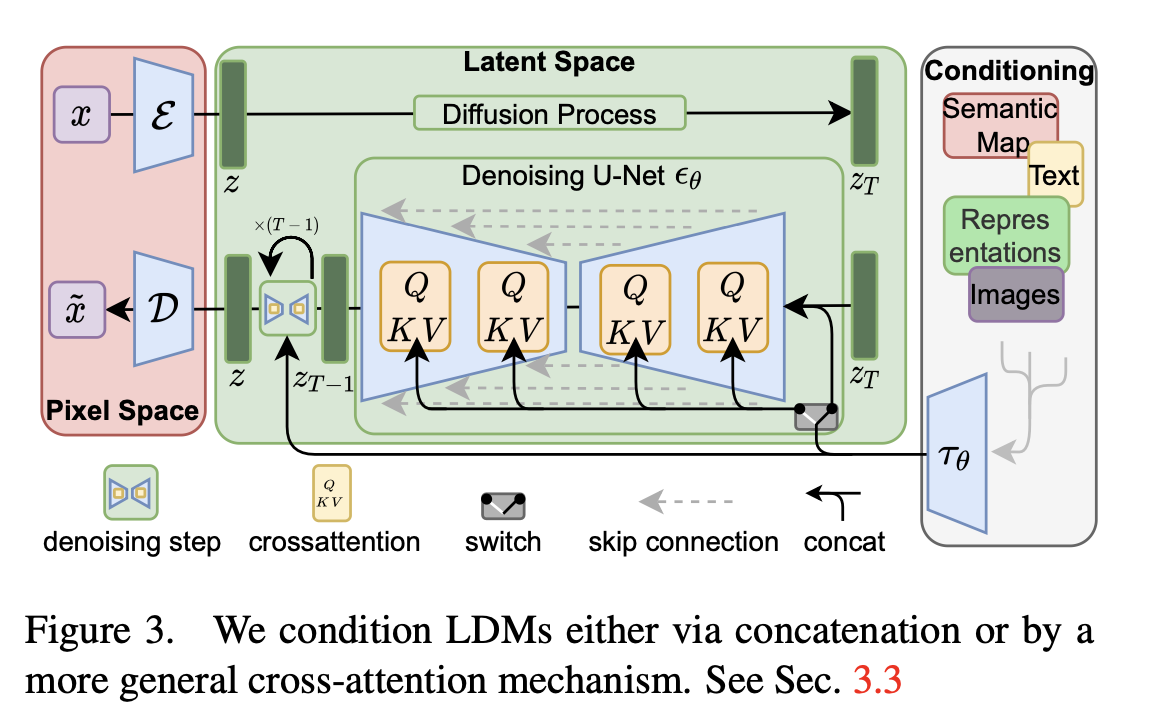
(Source: https://arxiv.org/abs/2112.10752)
The training process can be described in two phases: First, pretrain an autoencoder to encode input images into a lower-dimensional latent space to reduce complexity. Second, train diffusion models on the latent representations of the pretrained autoencoder.
Operating in latent space reduces the computational costs and complexity of diffusion models for training and inference and can generate high-quality results.
Another contribution of this paper is the cross-attention mechanism for general conditioning. So, next to unconditional image generation, the proposed latent diffusion model can be capable of inpainting, class-conditional image synthesis, super-resolution, and text-to-image synthesis – the latter is what made DALLE-2 and Stable Diffusion so famous.
Seven Other Paper Highlights of 2022
Here are short summaries of seven other papers that I had on my original top-10 list:
4) Gato
In A Generalist Agent, the researchers introduced Gato, which is capable of performing over 600 tasks, ranging from playing games to controlling robots.
5) Chinchilla
In Training Compute-Optimal Large Language Models the researchers found that it’s necessary to scale both the model size and the number of training tokens by the same factor to achieve optimal computation during training. They created a model called Chinchilla that, for example, outperformed Gopher using 4 times fewer parameters and 4 times more data.
6) PaLM
In PaLM: Scaling Language Modeling with Pathways, researchers proposed the PaLM model that shows impressive natural language understanding and generation capabilities on various BIG-bench tasks. To some extent, it can even identify cause-and-effect relationships.
7) Whisper
The Robust Speech Recognition via Large-Scale Weak Supervision paper introduced the Whisper model, which was trained for 680,000 hours on multilingual tasks and exhibits robust generalization to various benchmarks. I was very impressed with the Whisper model introduced in this paper. I used it for generating the subtitles for my Deep Learning Fundamentals – Learning Deep Learning With a Modern Open Source Stack and Introduction to Deep Learning classes.
8) Petraining Objectives
I enjoined reading quite a lot of deep-learning-for-tabular-data papers. I particularly liked the Revisiting Pretraining Objectives for Tabular Deep Learning paper because it highlights and reminded us how important it is to pretrain models on additional (typically unlabeled) data. (You can’t easily do this with tree-based models like XGBoost.)
9) Gradient Boosting Remains Relevant
Why do tree-based models still outperform deep learning on tabular data? The main takeaway is that tree-based models (random forests and XGBoost) outperform deep learning methods for tabular data on medium-sized datasets (10k training examples). But the gap between tree-based models and deep learning becomes narrower as the dataset size increases (here: 10k -> 50k). Unfortunately, this paper doesn’t include many state-of-the-art deep tabular networks, but it features a robust analysis and an interesting discussion. It is definitely worth reading.
10) ESMFold
The Evolutionary-scale prediction of atomic level protein structure with a language model paper proposed the largest language model for predicting the three-dimensional structure of proteins to date. It’s also faster than previous methods while maintaining the same accuracy. This model has created the ESM Metagenomic Atlas, the first large-scale structural characterization of metagenomic proteins, featuring over 617 million structures.

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!