What Are the Different Approaches for Detecting Content Generated by LLMs Such As ChatGPT? And How Do They Work and Differ?
Since the release of the AI Classifier by OpenAI made big waves yesterday, I wanted to share a few details about the different approaches for detecting AI-generated text.
This article briefly outlines the following four approaches to identifying AI-generated content:
- The AI Classifier by OpenAI
- DetectGPT
- GPTZero
- Watermarking
The AI Classifier
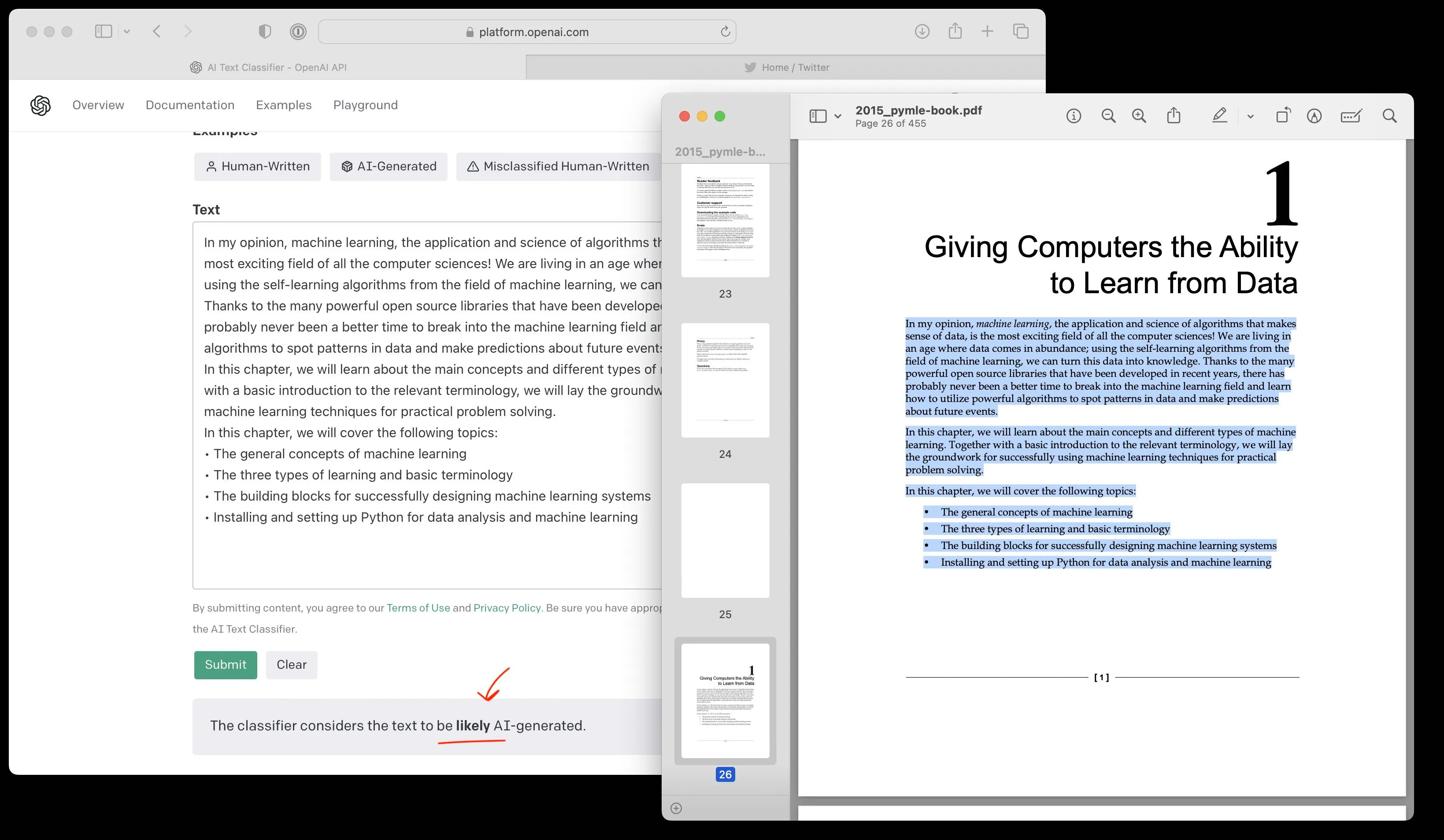
The AI Classifier by OpenAI made big headlines yesterday. Based on their website description, it’s a GPT model that is fine-tuned via supervised learning to perform binary classification – the training dataset consisted of human-written and AI-written text passages.
The probabilities are thresholded to obtain the five categories: very unlikely, unlikely, unclear if it is, possibly, or likely AI-generated.
Limitations: This method produces a significant portion of false negatives and false positives. According to the documentation, 30% of human-generated content flagged possibly or likely generated by an AI. Furthermore, the limitation when developing tis model is that the training data needs to be representative of the texts that future users feed it with.
Source: https://platform.openai.com/ai-text-classifier
DetectGPT
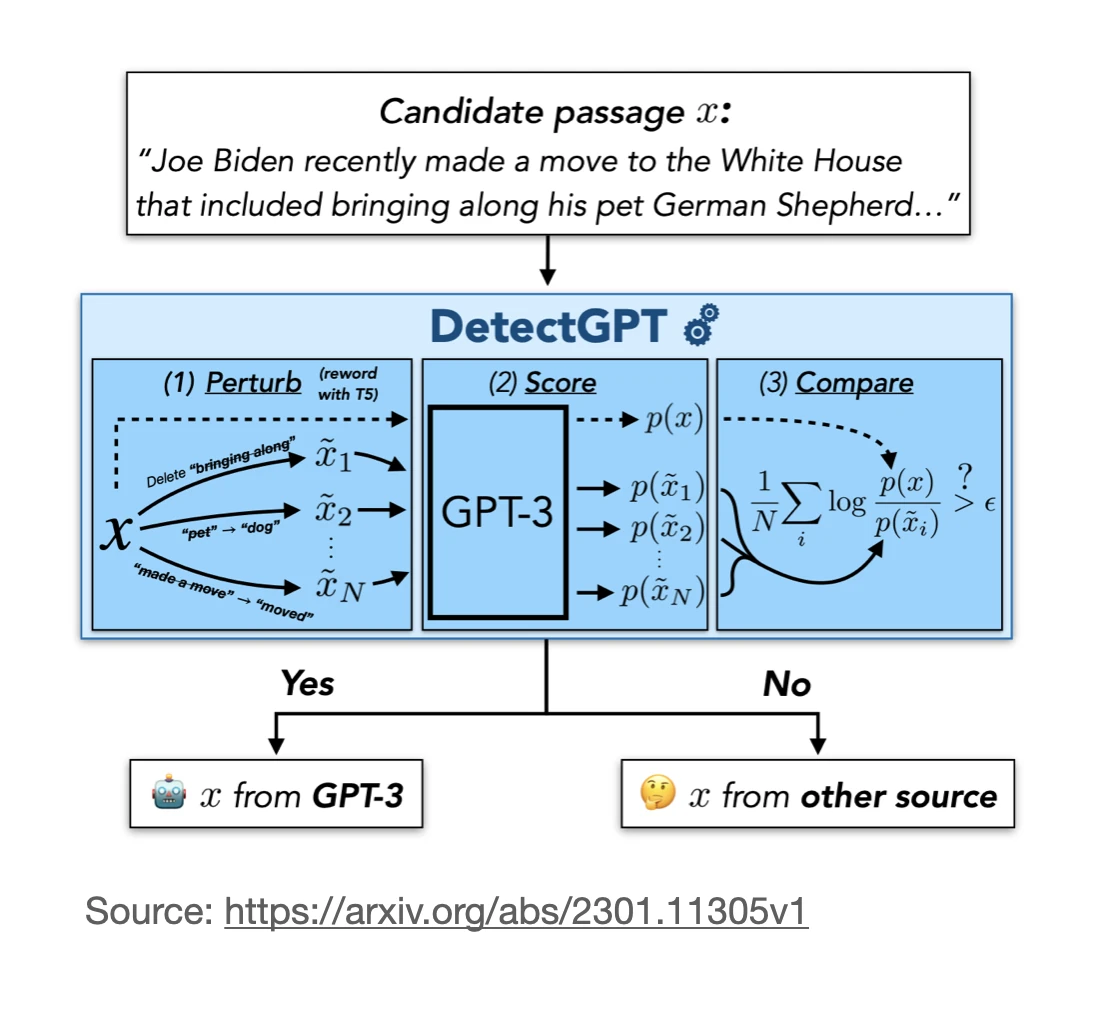
The DetectGPT method relies on generating the (log-)probabilities of the text. If an LLM produces text, each token has a conditional probability of appearing based on the previous tokens. Multiply all these conditional probabilities to obtain the (joint) probability for the text.
The DetectGPT method then perturbs the text: if the probability of the new text is noticeably lower than the original one, the original one was AI-generated. Otherwise, if it’s approximately the same, it’s human generated.
For example, consider the two sentences below, where the first sentence is the input sentence, and the second sentence is a perturbed sentence:
-
“This sentence is generated by an AI or human” => log-probability 1
-
“This writing is created by a an AI or person” => log-probability 2
- If log-proba 2 < log-proba 1: This text is AI-generated
- If log-proba 2 ~ log-proba 1: This text is human-generated
Limitations: The method requires access to the (log-)probabilities of the texts. This involves using a specific LLM model, which may not be representative of the AI model to generate the text in question.
Source: https://arxiv.org/abs/2301.11305v1
GPTZero
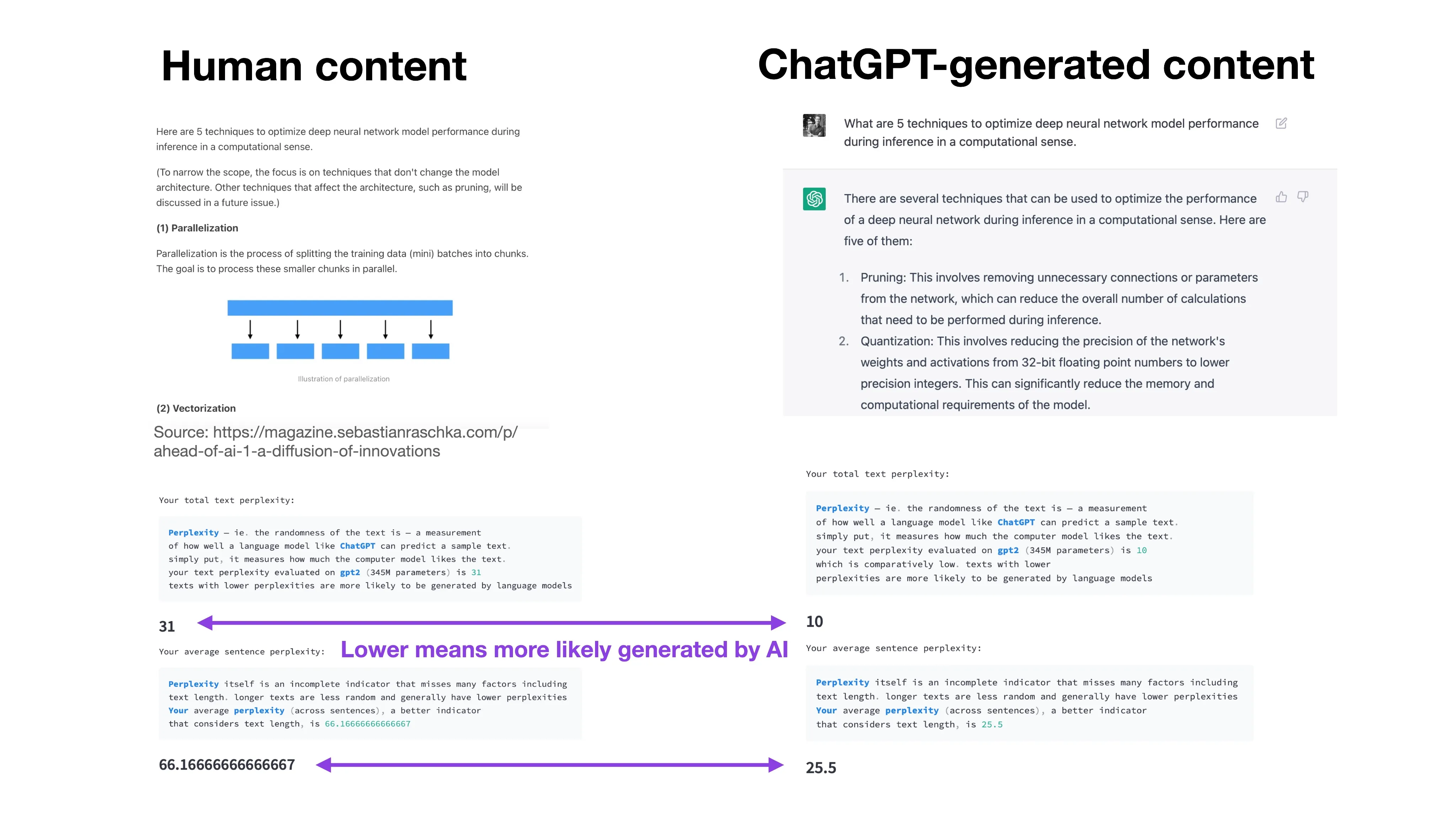
GPTZero is a simple linear regression model that estimates the perplexity of the input text (at least the first version I initially tested and wrote about a few weeks ago, https://etedward-gptzero-main-zqgfwb.streamlit.app).
The perplexity is related to the log-probability of the text mentioned for DetectGPT above. The perplexity is calculated as the exponent of the negative log-probability. So, the lower the perplexity, the less random the text. Large language models learn to maximize the text probability, which means minimizing the negative log-probability, which in turn means minimizing the perplexity.
GPTZero then uses the hypothesis that sentences with lower perplexity are more likely generated by an AI. In addition to the overall perplexity, GPTZero also reports the so-called “burstiness” of text. The burstiness is a plot of the perplexity scores for each sentence.
In contrast to the other methods discussed earlier, GPTZero does not recommend whether the text was AI-generated or not. Instead, it only returns the perplexity score for a relative comparison between texts. This is nice because it forces users to compare similar texts critically instead of blindly trusting a predicted label.
Limitations: See DetectGPT above. Furthermore, GPTZero only approximates the perplexity values by using a linear model.
Source: https://gptzero.substack.com
Watermarking
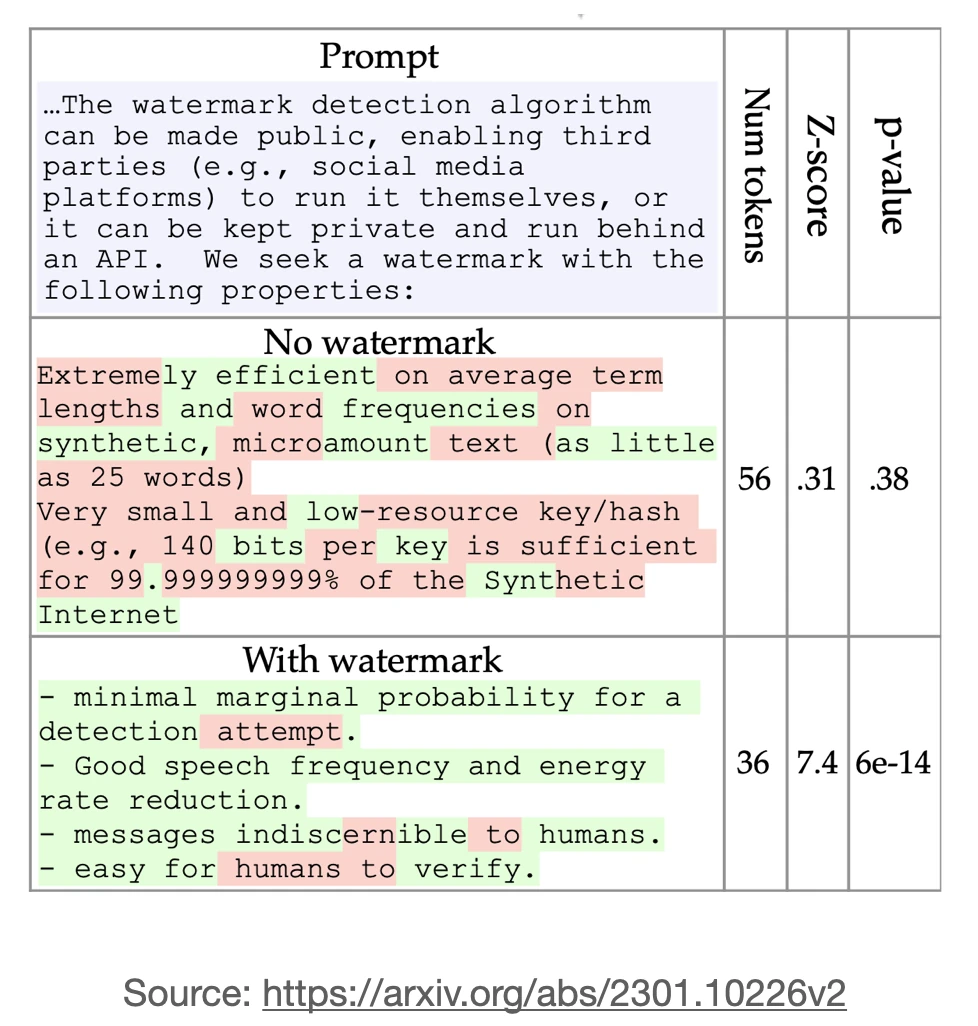
The proposed watermarking idea is to lower the probabilities of certain words so that they are less likely being used by the LLM. Or in other words, the watermarking method relies on an “avoid list”.
So, if a generated text contains these lower-probability words from the avoid list, the text is likely human-generated as the LLM tries to avoid to use these words.
Limitations: This requires that a person uses an LLM that has been modified with this avoid list. It is highly unlikely that this will happen: it’s like asking any Photoshop-like image editor to add a visible watermark to each image upon saving.
Also, If the avoid list is known, a human can also modify AI-generated text by manually including avoid list words to beat the detection method. Lastly, the avoid list can also lead to awkward-sounding sentences.
Source: https://arxiv.org/abs/2301.10226v2
This article is merely a short overview or outline of the different methods being developed to detect AI-generated content. If you want to read more about detecting AI-generated texts in detail, I highly recommend Melanie Mitchell’s Substack here.
Read Next
 Optimizing LLMs From a Dataset Perspective
Practical guide to improving LLM finetuning with better instruction datasets, covering data curation, prompt-output pairs, synthetic data, and experiment i
Optimizing LLMs From a Dataset Perspective
Practical guide to improving LLM finetuning with better instruction datasets, covering data curation, prompt-output pairs, synthetic data, and experiment i
 The NeurIPS 2023 LLM Efficiency Challenge Starter Guide
Large language models (LLMs) offer one of the most interesting opportunities for developing more efficient training methods. A few weeks ago, the NeurIPS..
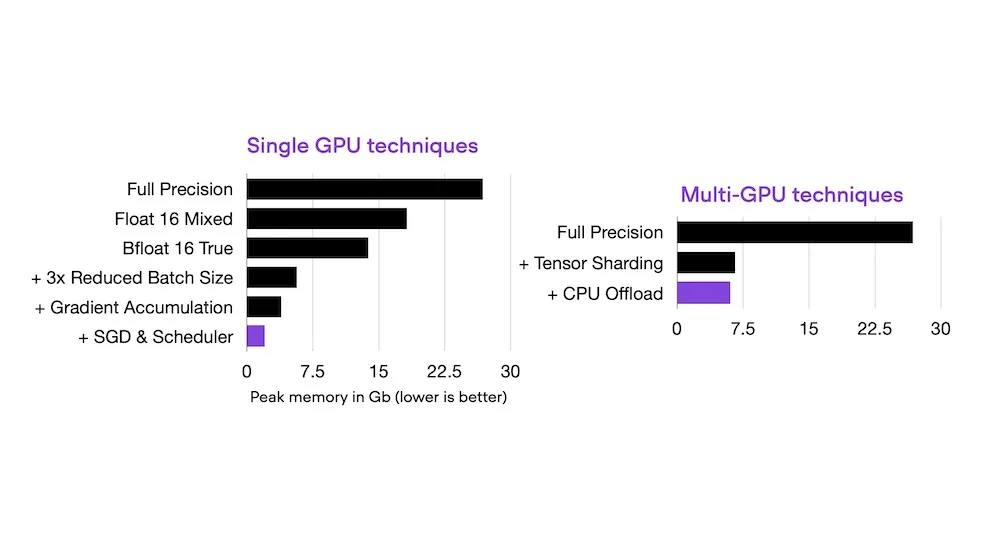
Optimizing Memory Usage for Training LLMs and Vision Transformers in PyTorch
Peak memory consumption is a common bottleneck when training deep learning models such as vision transformers and LLMs. This article provides a series of..
The NeurIPS 2023 LLM Efficiency Challenge Starter Guide
Large language models (LLMs) offer one of the most interesting opportunities for developing more efficient training methods. A few weeks ago, the NeurIPS..
Optimizing Memory Usage for Training LLMs and Vision Transformers in PyTorch
Peak memory consumption is a common bottleneck when training deep learning models such as vision transformers and LLMs. This article provides a series of..

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!