Curated Resources and Trustworthy Experts: The Key Ingredients for Finding Accurate Answers to Technical Questions in the Future
Conversational chatbots such as ChatGPT probably will not be able replace traditional search engines and expert knowledge anytime soon. With the vast amount of misinformation available on the internet, the ability to distinguish between credible and unreliable sources remains challenging and crucial.
Approximately correct but wrong answers
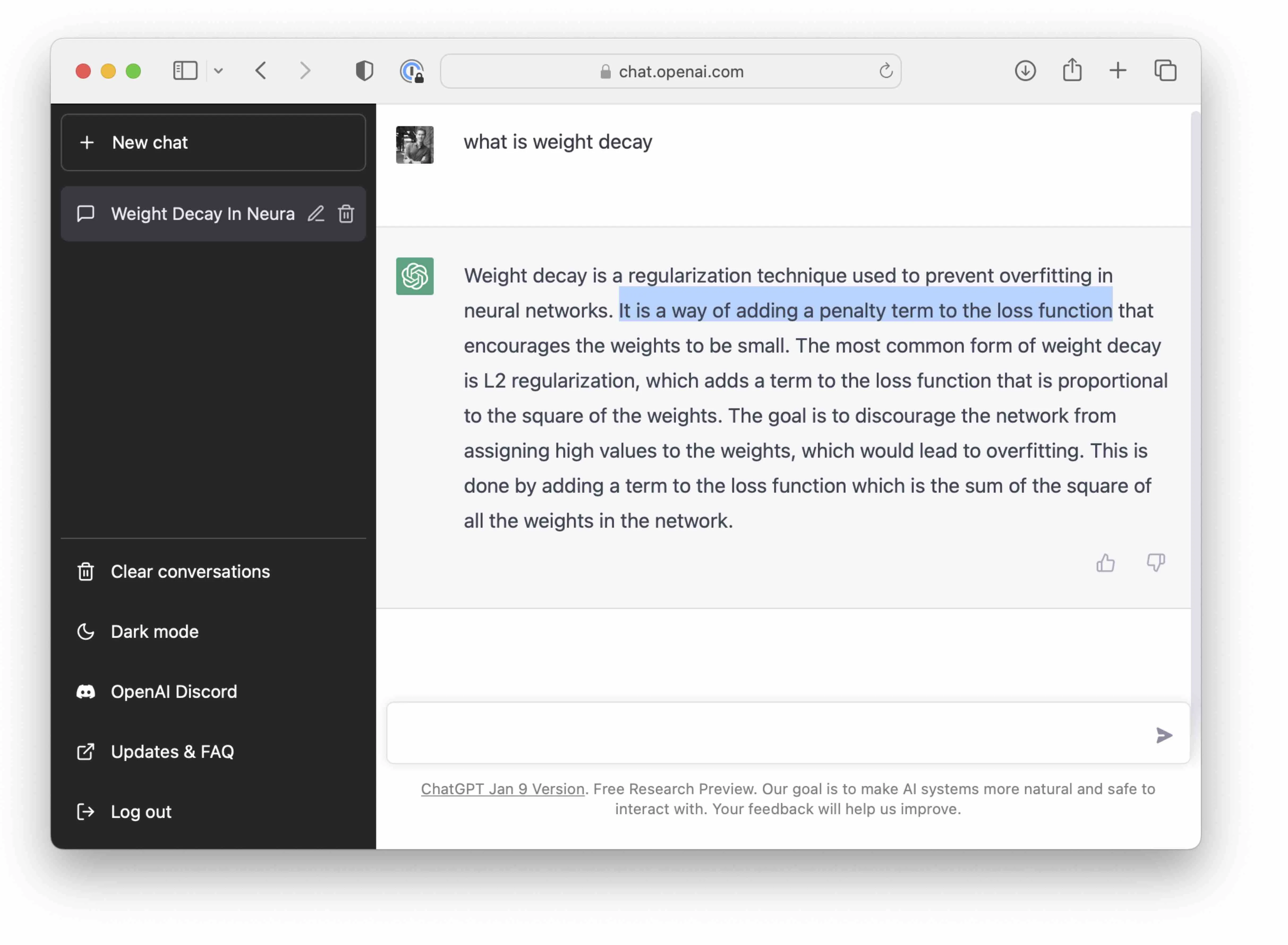
Consider asking ChatGPT to explain weight decay – a popular regularization technique in deep learning. Unfortunately, the answer is incorrect – it conflates weight decay with the related but slightly different \(L_2\)-regularization of a loss function:
“The most common form of weight decay is L2 regularization, which adds a term to the loss function that is proportional to the square of the weights. […] his is done by adding a term to the loss function which is the sum of the square of all the weights in the network.”
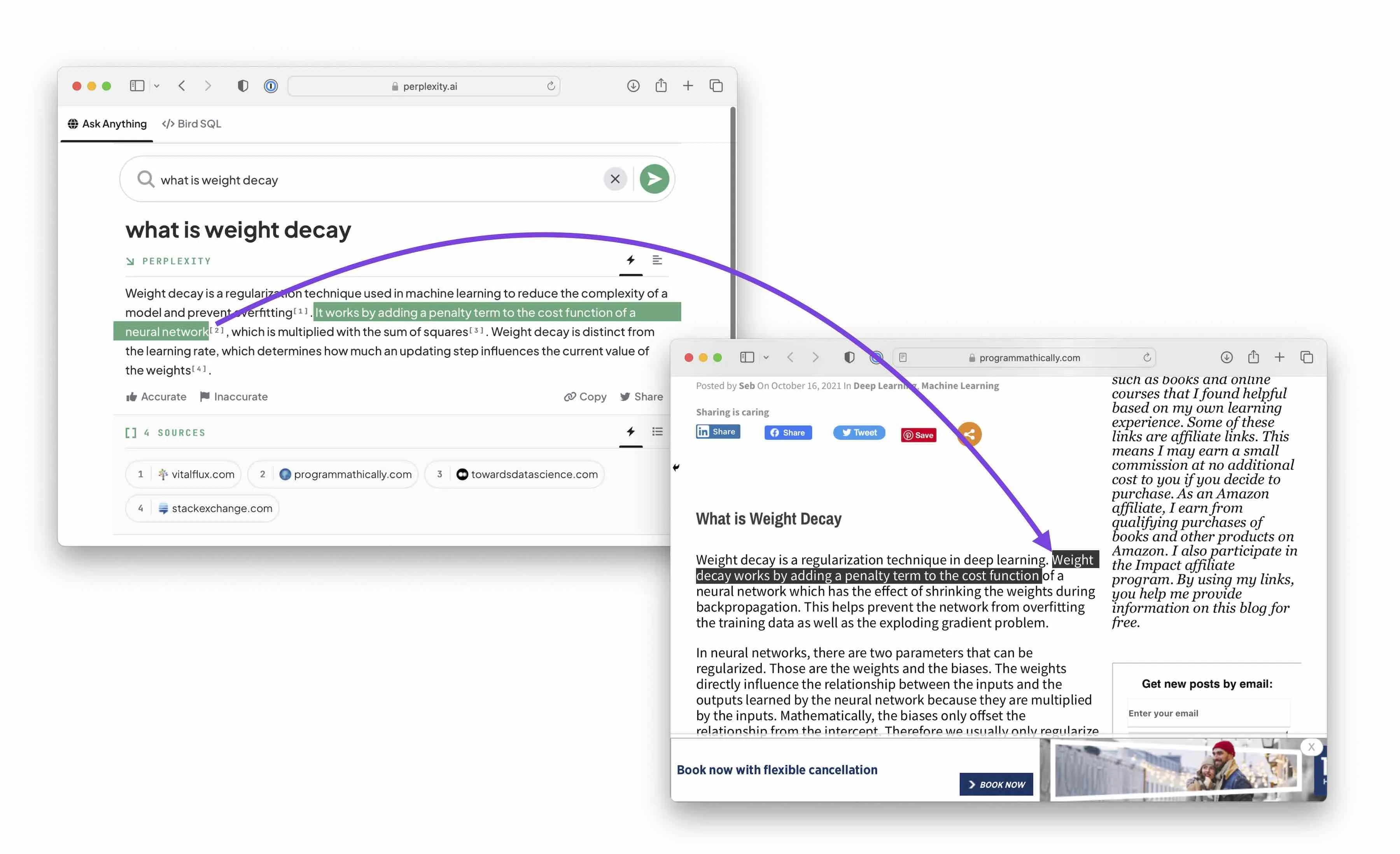
I then tried Perplexity AI, which is a large language model that references resources for the given information. Following these resources, I found that the issue is not the large language model (LLM) “dreaming up” these facts but the factual errors in the training data:
Weight decay works by adding a penalty term to the cost function of a neural network which has the effect of shrinking the weights during backpropagation.
One might argue that this can be fixed by only providing factually correct training data. This is of course possible but not yet feasible.
Addressing but not yet fixing the issue
Large language models require vast amounts of training data to learn to write grammatically correct and plausible texts. But grammatically correct doesn’t equal factually correct. To mitigate this issue with misinformation, researchers behind InstructGPT developed a 3-step approach:
- Fine-tune a pretrained LLM with human-generated prompts using supervised learning.
- Let humans rank different answers to various prompts on a 1-5 scale, and use this data to train a reward model.
- Use this reward model to the fine-tuned LLM from step 1.
This 3-step process is summarized in the illustration from the InstructGPT paper below:
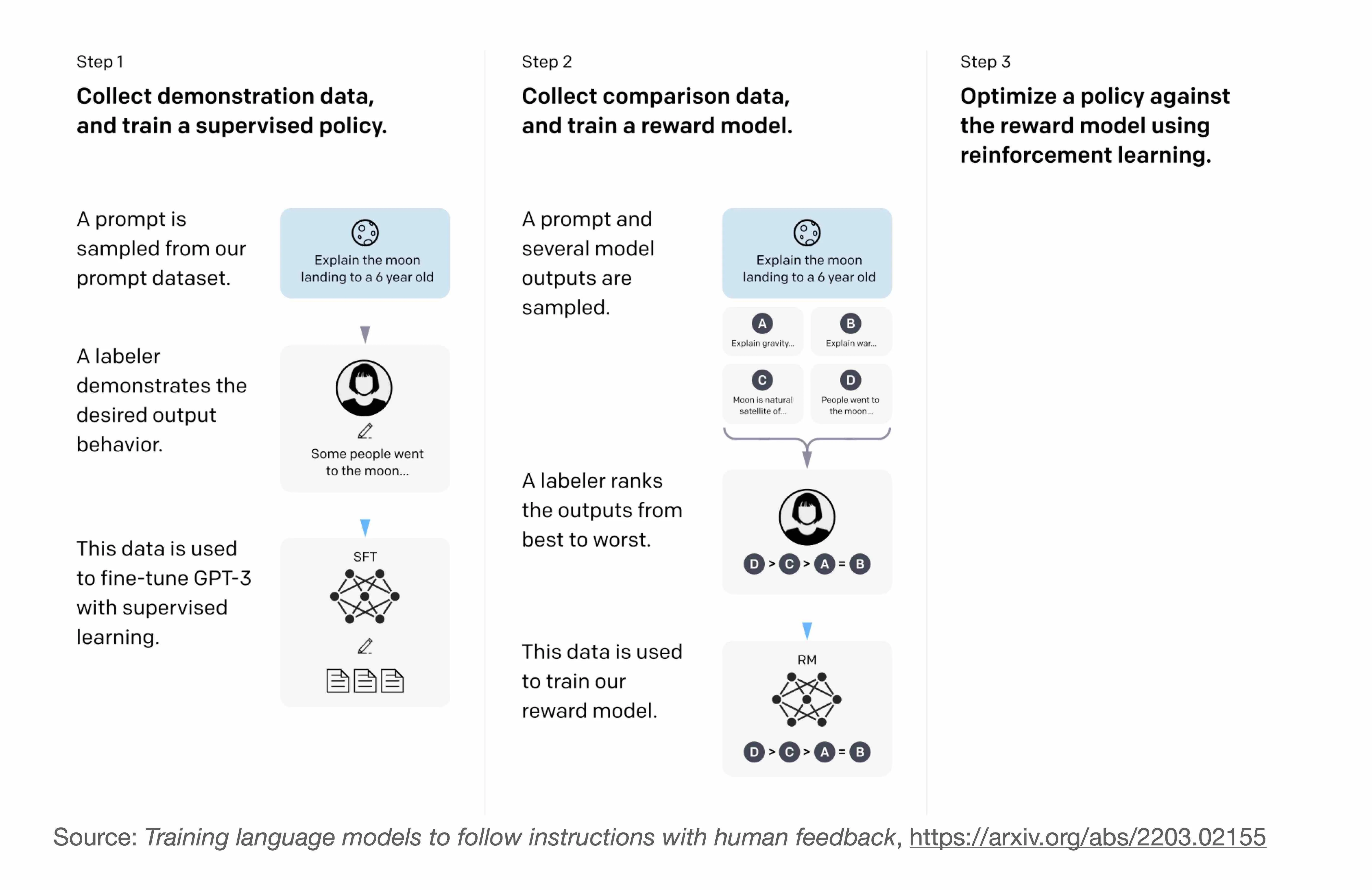
OpenAI hired 40 contractors to generate answers to prompts for developing InstructLLM via supervised fine-tuning and reinforcement learning with humans in the loop, as summarized in the figure above. While the exact details are not public yet, ChatGPT follows a similar recipe but involving a much larger quantity of human resources.
Creating correct answers to learn a correct answer – a resource dilemma
The dilemma is that current-gen LLMs require vast amounts of data, and even if you were hiring thousands of human experts to curate the training data we may end up with not enough data to fine-tune these models – because good-quality information on many topics is scarce.
Since the amount of factually correct information might be too scarce, the solution might be to create more factually accurate data to train these LLMs. The obvious question is, then: What is the benefit of creating multiple articles on weight decay as training fodder for ChatGPT if we can just read and refer to these resources directly?
Conclusion: LLMs can be useful but are not the solution to everything
Conversational chatbots such as ChatGPT are very impressive. They are also handy as a writing tool, for example, to rewrite clunky sentences. However, it remains important to evaluate the output of these models critically and use human judgment to determine their usefulness and applicability.
One of the trends we will hopefully see in the future is the return to curated resources by trustworthy experts if we are seeking factually correct answers to technical questions.
(In the meantime, I will stay tuned for next-generation LLMs incorporating reference citations into their answers. For instance, DeepMind plans to release its Sparrow model in 2023. So I will keep my “what is weight decay” query on standby until then.)
So, what is weight decay?
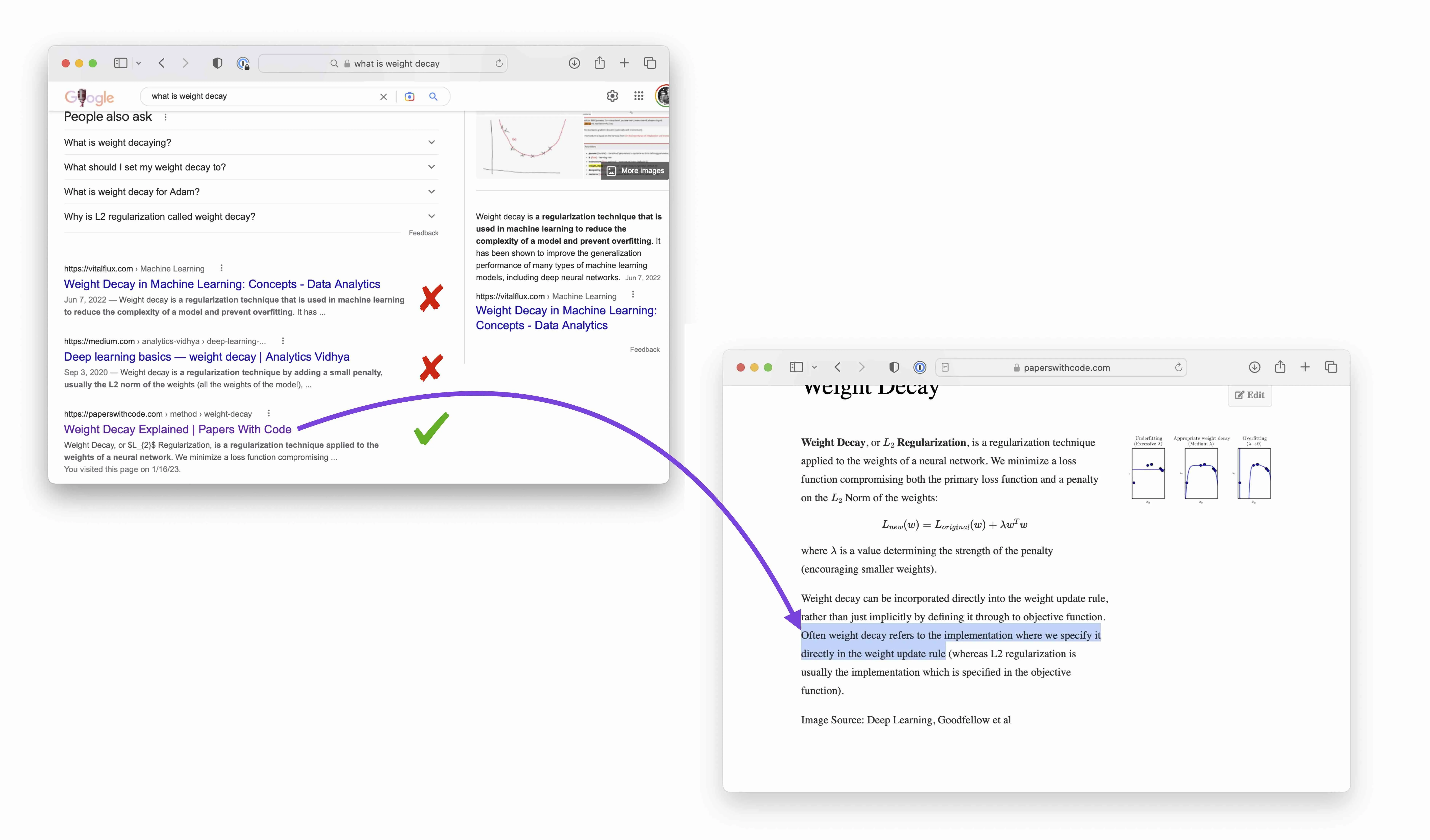
You read various wrong answers to the weight decay query above. If you are curious what the correct explanation is, even using traditional search engines like Google, it took a bit of digging to identify a trustworthy resource that gave a correct explanation:
“Weight decay can be incorporated directly into the weight update rule, rather than just implicitly by defining it through to objective function. Often weight decay refers to the implementation where we specify it directly in the weight update rule (whereas L2 regularization is usually the implementation which is specified in the objective function).”
Read Next
 Optimizing LLMs From a Dataset Perspective
Practical guide to improving LLM finetuning with better instruction datasets, covering data curation, prompt-output pairs, synthetic data, and experiment i
Optimizing LLMs From a Dataset Perspective
Practical guide to improving LLM finetuning with better instruction datasets, covering data curation, prompt-output pairs, synthetic data, and experiment i
 The NeurIPS 2023 LLM Efficiency Challenge Starter Guide
Large language models (LLMs) offer one of the most interesting opportunities for developing more efficient training methods. A few weeks ago, the NeurIPS..
Optimizing Memory Usage for Training LLMs and Vision Transformers in PyTorch
Peak memory consumption is a common bottleneck when training deep learning models such as vision transformers and LLMs. This article provides a series of..
The NeurIPS 2023 LLM Efficiency Challenge Starter Guide
Large language models (LLMs) offer one of the most interesting opportunities for developing more efficient training methods. A few weeks ago, the NeurIPS..
Optimizing Memory Usage for Training LLMs and Vision Transformers in PyTorch
Peak memory consumption is a common bottleneck when training deep learning models such as vision transformers and LLMs. This article provides a series of..

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!