Book Review: Deep Learning With PyTorch
-- A Practical Deep Learning Guide With a Computer Vision Focus and an Interesting Structure
After its release in August 2020, Deep Learning with PyTorch has been sitting on my shelf before I finally got a chance to read it during this winter break. It turned out to be the perfect easy-going reading material for a bit of productivity after the relaxing holidays. As promised last week, here are my thoughts.

Disclaimer I want to mention that I am not affiliated with the authors, and I have not received a review copy of this book. Everything I write below is my honest, unbiased opinion.
The main reason why this book piqued my interest was that I like reading, and as a long-term PyTorch user, I thought I might discover one or the other useful tip or trick in this book. Moreover, I was looking for a helpful resource for students in my deep learning class (STAT 453: Introduction to Deep Learning and Generative Models). In past semesters, I have been referring students to online tutorials as “further reading resources.” Still, I thought that having more options and a potentially more consistent and structured resource might be appreciated.
How the Book Is Organized
The book is organized into three parts, with approximately 470 pages of content in total. This sounds like a lot, but overall it was a relatively quick read due to its easy-going style and tone. As expected, there was a decent amount of code contained in the book. However, since deep learning is notoriously verbose (compared to machine learning with scikit-learn, for example), the authors made the right decision to abbreviate certain code sections while linking to the relevant parts in their GitHub repository. I think this was a good decision because it kept the book much more readable. In the following paragraphs, let me talk a little bit more about the three parts.
Part 1 (chapters 1-9) introduces the broad concepts behind PyTorch and deep learning. What’s worth noting is that it starts with a top-down approach, that is, using a pre-trained model. Then, it explains PyTorch in a bit more detail and explains multilayer perceptrons and convolutional neural networks for image classification on a fundamental level. I particularly liked the introduction to PyTorch, which is probably the best-organized resource on the topic I’ve seen so far. However, overall it remains on a beginner level – it’s more suited for newcomers than advanced practitioners.
Part 2 (chapters 9-14) offers a particularly interesting and fresh approach. The five chapters walk readers through a hands-on computer vision project from beginning to end. The project is centered around detecting cancerous nodules in CT scans (3D data) of lungs. The chapters are connected and read like a story, walking the reader through the individual components: data loading, segmentation, grouping, classification, analysis, and diagnosis. It’s also nice that the first chapter focuses on and emphasizes understanding the underlying data, which is a critical aspect in real-world projects and often neglected.
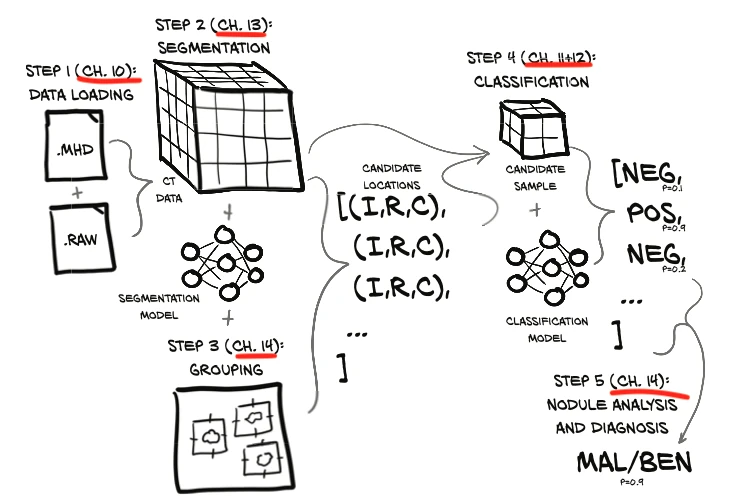
(Scan of a figure from chapter 9 outlining the topics covered in part 2.)
Lastly, part 3 (chapter 15) discusses the production and deployment aspects of PyTorch. It is more similar to part 1, where the sections are self-contained examples and explanations (as opposed to the sequential project in part 2). Part 3 consists of only one chapter and is thus relatively short. However, its brevity may be a good sign, indicating that PyTorch’s deployment tooling is not that complicated. In particular, it covers basic server deployment via Flask and Sanic, exporting PyTorch models via ONNX, PyTorch’s JIT for both tracing and scripting, and running PyTorch models on mobile. Although this is not relevant for my research needs, I really enjoyed this part since it was well structured and concise, and most of it was very new to me. For example, I found the explanation of the differences between PyTorch JIT’s tracing and scripting very helpful. Since you may wonder about the differences between the two as well, let me go on a little tangent below.
Tangent: About TorchScript
As you may know, PyTorch (similar to most other scientific computing libraries, for example, NumPy) uses optimized C++ code under the hood for performance reasons. Python merely acts as an API “glue” that makes these functions more accessible. Most people (me included) use PyTorch via its Python API. However, there is also a C++ API (its distribution is called LibTorch). This can come in handy for deployment and production purposes, where you may not have access to or want to avoid a Python runtime.
Given that the PyTorch API relies on the C++ code anyway, we can convert back our Python-PyTorch code into C++ code via a TorchScript graph or intermediate representation (also known as TorchScript IR). Both tracing and scripting via the Torch JIT let us do this. Below I sketched out my understanding of how these different concepts are related and connect.
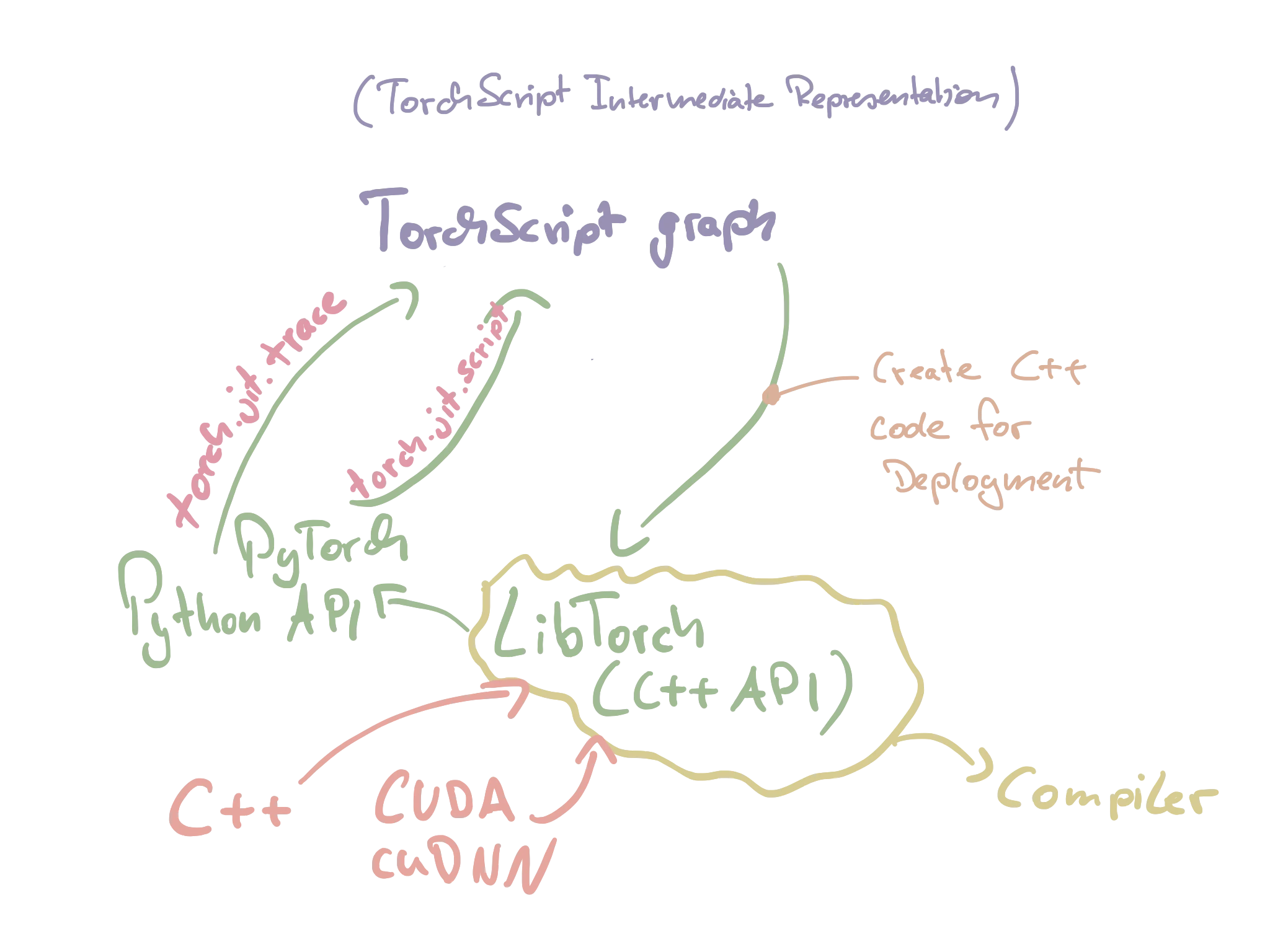
(Sketch of my understanding of how things connect and work under the hood)
Torch’s C++ autograd interface can then use TorchScript IR graphs for deployment by taking Python out of the equation (or rather computation). As mentioned above, this is especially attractive if the target environment doesn’t have a Python runtime or if you want to boost the performance of your DL models. By the way, it turns out that most deep learning related code in PyTorch is already highly optimized by calling C++ and CUDA code. Consequently, Python is probably not a big showstopper for performance (and this is why I think that Python will probably stay relevant for deep learning for a long time). To quote the authors:
Quite often, Python is said to lack speed. While there is some truth to this, the tensor operations we use in PyTorch usually are in themselves large enough that the Python slowness between them is not a large issue. For small devices like smartphones, the memory overhead that Python brings might be more important. So keep in mind that frequently, the speedup gained by taking Python out of the computation is 10% or less.
Now, tracing via torch.jit.trace tracks the computation via sample inputs. If we have a for-loop with five iterations, as shown below, this for-loop is expanded to 5 individual steps:

A disadvantage of the tracing approach shown above is that once we traced the function into the intermediate representation (which can serve as input for the compiler), the compiled function is specific to inputs of size five, as the TracerWarning above indicates.
The JIT’s script approach is more flexible than tracing as it can convert the function without dependence on its inputs:
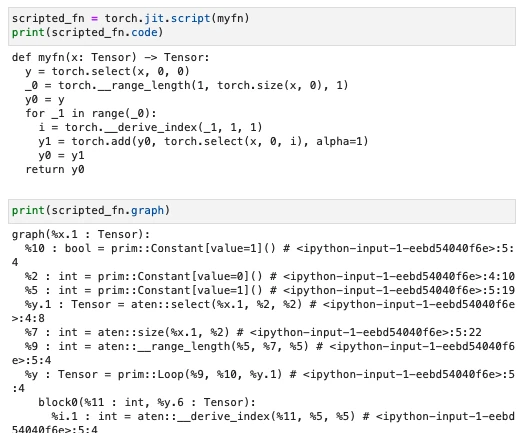
In practice, it is more common to use the handy @torch.jit.script function decorator. In any case, after this short tanget, the next section continues the discussion of the book itself.
What To Expect: Breadth and Depth
Overall, the book is kept very simple and accessible. It covers the basics of deep learning and PyTorch and does not assume any prior knowledge except being comfortable with Python. The book also remains entirely equation-free (okay, except for one figure that illustrates the softmax function). Quoting the authors,
“We’d rather keep things simple so that we can focus on the fundamental concepts; the clever stuff can come later, once you’ve mastered the basics”
In this way, it is the opposite of Goodfellow et al.’s Deep Learning book, which is code-free and more recommended towards those who have some basic deep learning experience. Actually, both books are complementary (for instance, beginners may start with the PyTorch book to get a basic understanding and then dive into more details with Goodfellow et al.’s book).
One aspect readers should be aware of is that this book is heavily computer vision-focused, and all neural network examples are given in the context of image data. Other data modalities like text are not covered. The book is also restricted to multilayer perceptrons and convolutional architectures (U-Net and ResNet); different types of neural network architectures such as recurrent neural networks, graph neural networks, autoencoders, generative adversarial networks, and transformers are outside the scope of this book.
Interesting Aspects That Stood Out
Besides the interesting structure overall (for instance, the project-focused Part 2 that reads like a story), I like that the book starts with a top-down approach via a pre-trained model for image classification. Given that deep learning code can be very verbose, I can imagine that this lowers the entry barrier and makes deep learning less scary to newcomers. Also, the colloquial language and occasional humor make this book a relatively easy-going read. Many code snippets are directly annotated. Something I am doing in lecture slides but haven’t seen done before in books. Very effective.
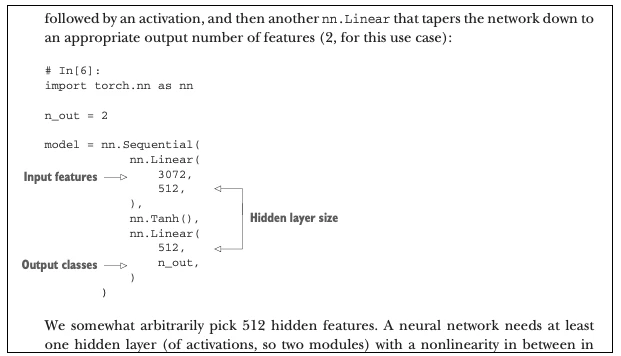
(Example of the code snippet annotation used in the book.)
General Verdict
Overall, I think that this is a great book for beginners who are entirely new to deep learning. Those who are already deep learning experts and are specifically interested in PyTorch may find the book a bit too introductory, but I think that reading chapter 3 is still worthwhile. It is a nice, self-contained introduction to the PyTorch basics that I find nicer and more organized than other online resources.

(Overview of the contents covered in chapter 3.)
I do think that the book may work well as a complementary companion for deep learning classes that involve coding aspects and class projects. Especially the project-walkthrough in part 2 could help students with structuring their class projects.
Bonus: Leviathan Wakes
As a small bonus, I wanted to say a few words about the other book I mentioned in the original tweet, since some people were also (more) interested to hear about it.

(Source: https://twitter.com/rasbt/status/1348680806487760897?s=20)
Leviathan Wakes by James S. A. Corey (the pen name of Daniel Abraham and Ty Franck) is a good old-fashioned space opera – another easy-going and enjoyable read. It’s set in the near but not too distant future (maybe the 22nd century?), where humans have colonized Mars and the asteroid belts between Mars and Jupiter. While it is not a hard science fiction book, the setting seems believable and plausible while primarily focused on delivering an entertaining story. Leviathan Wakes is the first installment of the “The Expanse” series. Note that there is also a recent TV show based on this series. However, I haven’t watched it so I can’t say much about it.
Most science fiction books focus on particular aspects of space that make them unique. Leviathan wakes’ focus is on gravity and radiation. For example, accelerating space ships change the gravity pull, and the characters are equipped with magnetic boots that are used when required. This is all described with attention to detail, making the world (or planets and space) very believable.
The main story is centered around two protagonists. One of these two characters is a stereotypical righteous hero type, whereas the other takes the form of an anti-hero. The latter reminded me a lot of Deckard from Blade Runner, and the “Belt” locations had strong noir detective story vibes, creating an exciting atmosphere.
An interesting aspect about this book is that the chapters are written from the two main characters’ perspectives, alternating the viewpoints between each chapter. These perspective shifts reminded me of the “A Song of Fire and Ice” series, but since it is focused on two characters’ perspectives only, it is much easier to keep track of the relatively straightforward but intriguing storyline (it is all about a mystery that slowly unfolds).
Overall, I enjoyed this book. It doesn’t have the sarcastic humor of a Joe Abercrombie book that I like, nor is it as unconventional as Ancillary Justice. Still, It was an action-packed, easy read with some interesting story aspects and a great noir atmosphere that were just perfect for a light evening read after a hard days’ work. I enjoyed it enough that I am sure to check out the other books in the series.
Read Next

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!