MusicMood
– A Machine Learning Model for Classifying Music by Mood Based on Song Lyrics
In this article, I want to share my experience with a recent data mining project which probably was one of my most favorite hobby projects so far. It’s all about building a classification model that can automatically predict the mood of music based on song lyrics.
Links
- Try the MusicMood webapp
- Go to the MusicMood GitHub repository
- View the project presentation on SpeakerDeck
- A more technical report on arXiv
Sections
About the Project
The goal of this project was to build a classifier that categorizes songs into happy and sad. As follow-up to my previous article Naive Bayes and Text Classification I - Introduction and Theory, I wanted to focus on the song lyrics only in order to build such a classification model ‒ a more detailed technical report can be found here.
Data collection, pre-processing, and model training was all done in Python using Pandas, scikit-learn, h5py, and the Natural Language Toolkit ‒ a very smooth and seamless experience up to the point where I tried to deploy the web app powered by Flask, but more on that later.
In hope that it might be useful to others, I uploaded all the data and code to a public GitHub repository, and I hope that I provided enough descriptive comments to outline the workflow.
Why I Was Interested in This Particular Project
I have always had a big passion for the “data science” field which is one of the reason why I ended up pursuing a PhD as computational biologist who solves problems in the fields of protein structure modeling and analysis. About a year ago, I had the pleasure to take a great course about research in statistical pattern recognition that really fascinated me. Since I really enjoy music (classic rock in particular) and always wanted to take a dive into Python’s web frameworks, this suddenly all came together.
Data Collection and Exploratory Analysis
When I was brainstorming ideas about this project, I had no idea if there were freely available datasets that I could use. I soon found literature about related projects were the authors used hand-labeled datasets for mood prediction. I couldn’t find a source for downloading those datasets though, and those datasets seemed to have too many mood labels for my taste anyway which I thought could have a negative impact on the predictive performance. For this project, I just wanted to focus on the two classes happy and sad, because I thought that a binary classification based on song lyrics only might already be challenging enough for a machine learning algorithm based on text analysis.
The Million Song Dataset and Lyrics
Next, I stumbled upon the Million Song Dataset, which I found quite interesting. There is also the related musiXmatch catalog which provides lyrics for the Million Song Dataset. However, the lyrics in musiXmatch are already pre-processed, and my plan was to compare different pre-processing techniques. Plus I thought that the creation of an own mood-labeled song lyrics dataset might be a good exercise anyway. So I wrote some simple scripts to download the lyrics from LyricsWiki, filtered out songs for which lyrics were not available, and automatically removed non-English songs using Python’s Natural Language Toolkit.
Mood Labels - Where to Get Them?
So far so good, now that I collected a bunch of songs and the accompanying lyrics, the next task was to get the mood labels. In my first attempt, I downloaded user-provided tags from Last.fm, but I soon found out that tags like happy and sad (and other related adjectives) were only available for a very small subset of songs and very, very contradictory since being incomplete or out of context. Thus, I decided to do it the hard way and hand-label a subset of 1200 songs: 1000 songs for the training dataset and 200 songs for the validation dataset. There is no question about it that associating music with a particular mood is a somewhat subjective task, and if the labels are provided by a single person only, it unarguably introduces another bias. But let me explain later in the Webapp section how I am planning to extend the dataset and want to deal with this bias.
Labeling Data Can Actually Be Fun
Eventually, I ended up listening to 1200 songs while reading the lyrics. Of course, this sounds very tedious, however, I have to say that I also enjoyed this task, since I discovered a lot of good and interesting songs during this process! I used the following guidelines to assign the happy and sad mood labels: If the song had a somewhat dark theme, e.g., violence, war, killing, etc. (unfortunately there were quite a few songs matching these criteria), I labeled it as sad. Also, if the artist seemed to be upset or complaining about something, or if the song was about a “lost love,” I also labeled it as sad. And basically everything else was labeled as happy.
Exploratory Visualization to Satisisfy Curiosity
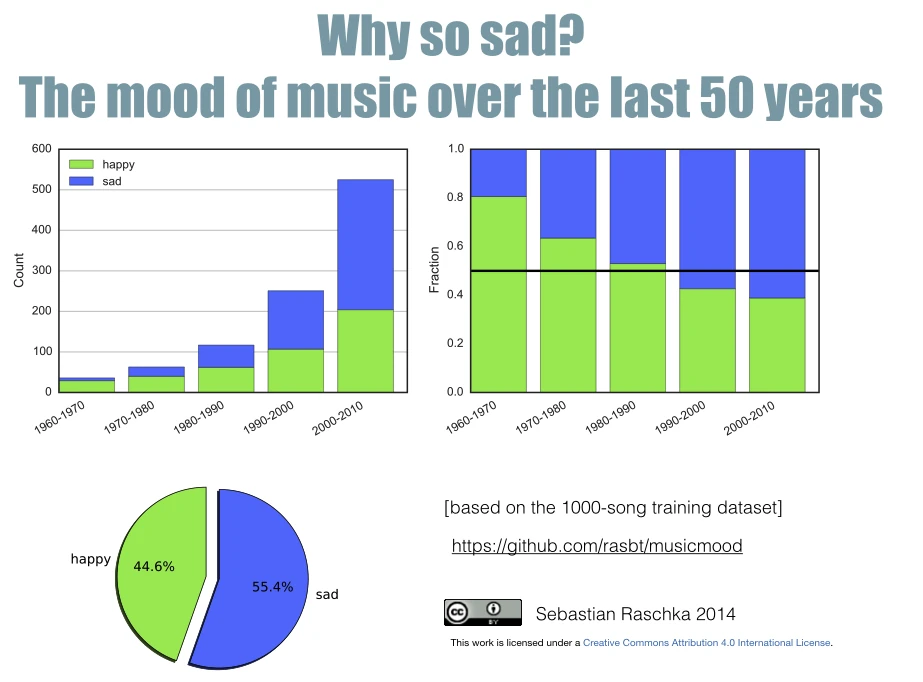
After I finished labeling the 1000-song training dataset, I was really tempted to do some exploratory analysis and plotted the number of happy and sad songs over the years. I found the results really interesting: Although there is a large bias towards more recent releases in the Million Song Dataset, there seems to bea trend: Unfortunately, music seems to become sadder over the years.
Model Selection and Training
Naive Bayes - Why?
As I mentioned in the introduction, one reason why I focused on naive Bayes classification for this project was to have an application for the previous Naive Bayes and Text Classification I - Introduction and Theory article. However, since I was also planning to create a small web app, I wanted to have a computationally efficient classifier. Some of the advantages of naive Bayes models are that they are pretty efficient to train in the batch-learning mode while they are also very compatible to on-line learning (i.e., updates on-the fly when new labeled data arrives). By the way, the predictive performance of naive Bayes classifiers is actually not too bad in context of text categorization. Studies showed that naive Bayes models tend to perform well given small sample sizes [1] and they are successfully being used for similar binary text classification tasks such as e-mail spam detection [2]. Other empirical studies have also shown that the performance of naive Bayes classifier for text categorization is comparable to support vector machines [3][4].
[1] P. Domingos and M. Pazzani. On the optimality of the simple
bayesian classifier under zero-one
loss.
Machine learning, 29(2-3):103–130, 1997.
[2] M. Sahami, S. Dumais, D. Heckerman, and E. Horvitz. A bayesian
approach to filtering junk
e-mail.
In Learning for Text Categorization: Papers from the 1998 workshop,
volume 62, pages 98–105, 1998.
[3] S. Hassan, M. Rafi, and M. S. Shaikh. Comparing svm and naive
bayes classifiers for text categorization with wikitology as knowledge
enrichment.
In Multitopic Conference (INMIC), 2011 IEEE 14th International, pages
31–34. IEEE, 2011.
[4] A. Go, R. Bhayani, and L. Huang. Twitter sentiment
classification using distant supervision. CS224N Project
Report,
Stanford, pages 1–12, 2009.
Grid Search and the Final Model
I especially want to highlight the great GridSearch implementation in scikit-learn that made the search for the “optimal” combination between pre-processing steps and estimator parameters very convenient. Here, I focussed on optimizing precision and recall via the F1-score performance metric rather than optimizing the overall accuracy ‒ I was primarily interested in filtering out sad songs; one might argue that this could be an interesting application to remove all the sad stuff from one’s music library.
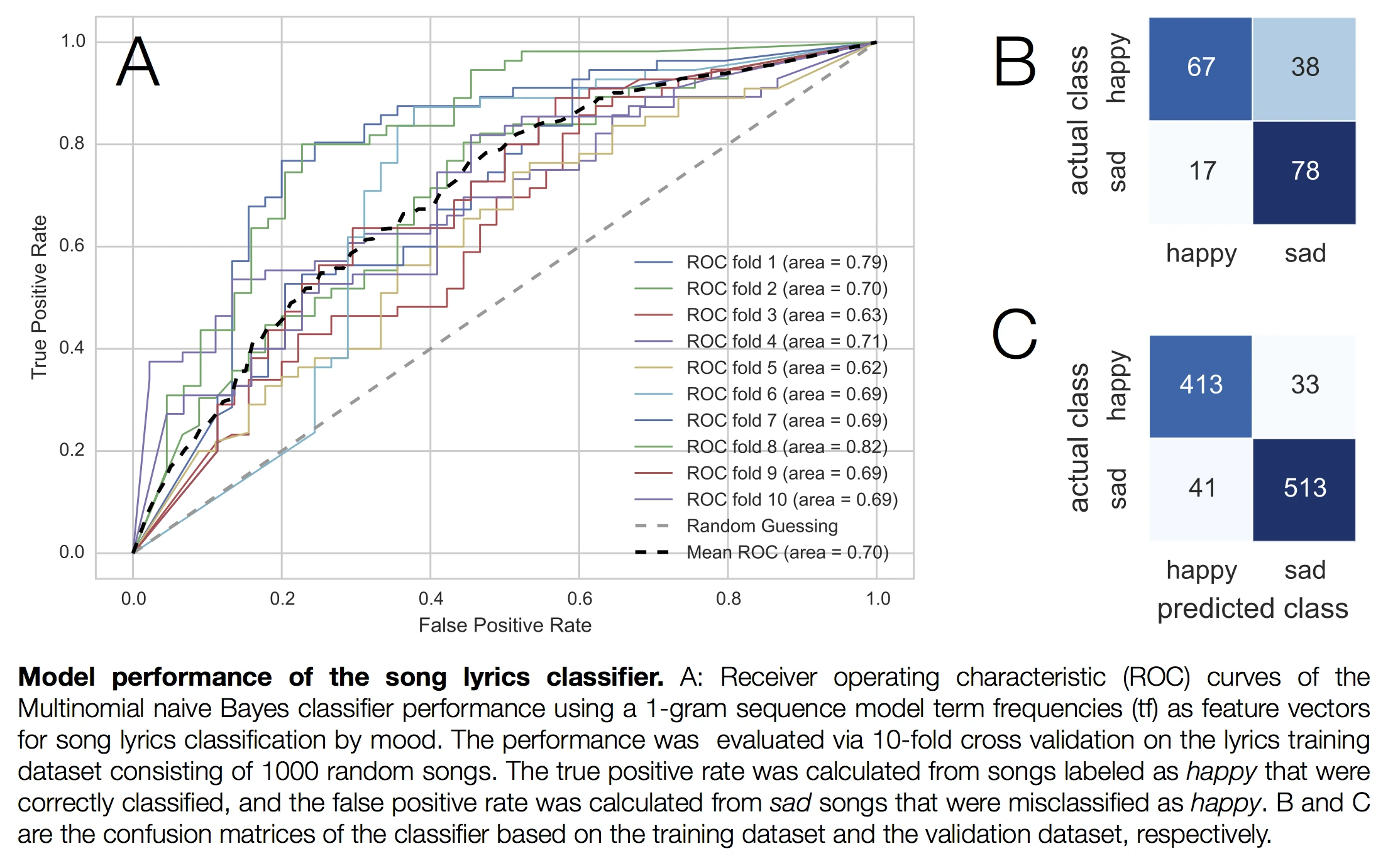
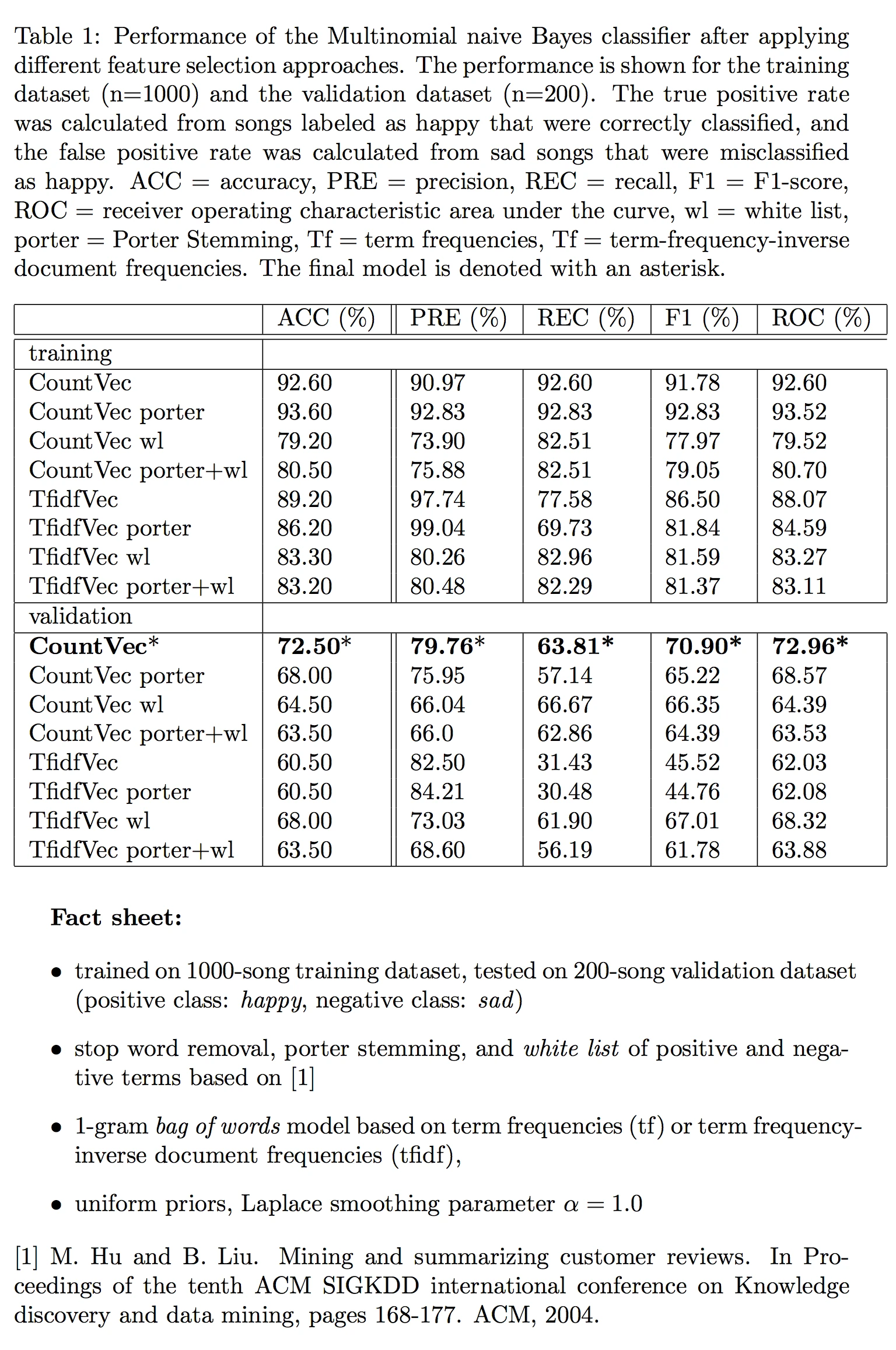
I don’t want to go into too much detail about the model selection in this article (since this will be part of a separate report), so I will just provide a very brief overview of the final model choice: The combination of 1-gram tokenization, stop word removal and feature vectors based on term frequencies in combination with a multinomial naive Bayes model seemed work best (in terms of the F1-score). However, the differences between the different pre-processing steps and parameter choices were rather minor except for the choice of the n-gram sequence lengths. You’ll find a summary of the final model below.
Deploying the Web app
I was particularly looking forward to part about turning the the final classifier into a web app. I have never done this before, and I was really eager to dive into Django or Flask. After browsing through some introductory tutorials, I decided to go with Flask, because being more lightweight it seemed to be a little bit more appropriate for this task. Embedding the classifier into a Flask web framework was actually way more straightforward than I initially thought ‒ Flask is just such a nice library and really easy to learn!
The Magic Number 500
However, the hard part (and probably the most challenging part of this whole project) was actually to deploy the app on a web server. The problems started when I set up a new Python environment on my bluehost server (I have a “starter” shared hosting plan). After I eventually got all the C-extensions compiled and installed “properly,” there was another thing to deal with in order to make sure that the Apache server digests my code: FastCGI. Luckily, there was this nice Flask tutorial to also overcome this challenge. Okay, theoretically I was all set ‒ at least I thought so. When I tried to use the web online for the first time, I remember that everything worked fine. Nice, after I tested the Flask app locally, the app also seemed to work on the web server! Unfortunately, though, the initial joy of the work didn’t last very long when I saw the server throwing “500 Internal Server Error”s once in a while (or rather 80% of the time). I literally worked through hundreds of troubleshooting guides and couldn’t find any reason why. In this particular case, no error message was written to the error log, which was different, for example, when I provoked other 500 errors intentionally.
Pythonanywhere to the Rescue
Eventually, I narrowed it down to the parts of the code where scikit-learn/scipy/numpy code was executed. Thus, my conclusion was that something with the C-libs probably caused the hiccups on this particular server platform. I also contacted the help staff and scripters at bluehost, but, unfortunately, they also couldn’t tell me anything about the particular cause of this issue. At this point, I was pretty much frustrated, since I put a lot of effort into something that didn’t seem to work for unexplained reasons. Still being curious if there was a general issue with my code, I just signed up for a free account at pythonanywhere ‒ and see what happened: Without having to install any additional Python libraries, my app just worked magically. However, I will probably try out some other things on the bluehost server in future, snce I don’t like this sort of “unfinished business,” and I am really looking forward to any sort of tips and suggestions that could help with resolving this issue.
As you can see, although I used a 10-fold cross-validation approach in the modeling selection process the model is still quite prone to over-fitting. The rather small training dataset might be one of the factors, which can hopefully be overcome in future.
Future Plans
Are There Any Plans to Update the Classifier?
Yes! My initial plan was to implement the naive Bayes classifier in an on-line learning mode so that it will be updated every time a user provides feedback about a classification. However, my feeling is that there will be a growing bias towards a certain subset of the most popular contemporary songs. Because I am also very eager to extend the training dataset for other analyses, e.g., comparisons of different machine learning algorithms and performance comparisons with regard to different training dataset sizes, I opted for another solution. Right now, I save the songs, lyrics, and suggested mood labels to a database if a user provides voluntary feedback about the prediction. After certain time intervals, I am planning to re-train and re-evaluate the model to hopefully improve the predictive performance and gain some interesting insights. The mood label assignment is highly subjective of course, thus, I am saving multiple mood labels per song to the database so that the “ground truth” label can be determined by majority rule. Also, this can open a door to some interesting regression-based analysis.
What About Sound Data?
I thought about including sound data in the classification. However, I think the challenge is that sound data is hard to obtain. Sure, there are those HDF5 files in the Million Song Dataset with pre-extracted sound features, but what about new songs that are not in the training dataset? Maybe data streaming from YouTube could be a possibility to be explored in future.
Read Next
 Scientific Computing in Python: Introduction to NumPy and Matplotlib
Beginner's guide to NumPy and Matplotlib for scientific computing: arrays, indexing, broadcasting, linear algebra, and plotting with Python code examples.
Scientific Computing in Python: Introduction to NumPy and Matplotlib
Beginner's guide to NumPy and Matplotlib for scientific computing: arrays, indexing, broadcasting, linear algebra, and plotting with Python code examples.
 Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
 Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...
Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!