Turn Your Twitter Timeline into a Word Cloud
– using Python
Turn Your Twitter Timeline into a Word Cloud Using Python
Last week, I posted some visualizations in context of “Happy Rock Song” data mining project, and some people were curious about how I created the word clouds. I thought it might be interesting to use a different dataset for this tutorial: Your personal twitter timeline.

Sections
Requirements
Before we get started, I want to list some of the required packages to make this work!
Below, you find a list of the basic packages which can be installed via
pip install <package_name>
And the Python (2.7)
wordcloud package by Andreas
Mueller can be installed via
pip install git+git://github.com/amueller/word_cloud.git
Note that wordcloud requires Python’s imaging library
PIL. Depending on the
operating system, the installation and setup of PIL can be quite
challenging; however, when I tried to install it on different MacOS and
Linux systems via conda it
always seemed to work seamlessly:
conda install pil
Let me use my handy watermark
extension to summarize the different packages and version numbers that
were used in my case to download the twitter timeline and create the
word cloud:
%load_ext watermark
%watermark -d -v -m -p twitter,pyprind,wordcloud,pandas,scipy,matplotlib
28/11/2014
CPython 2.7.8
IPython 2.1.0
twitter 1.15.0
pyprind 2.8.0
wordcloud 1.0.0
pandas 0.14.1
scipy 0.14.0
matplotlib 1.3.1
compiler : GCC 4.2.1 (Apple Inc. build 5577)
system : Darwin
release : 14.0.0
machine : x86_64
processor : i386
CPU cores : 2
interpreter: 64bit
A. Downloading Your Twitter Timeline Tweets
In order to download our twitter timeline, we are going to use a simple
command line tool
twitter_timeline.py.
The usage is quite simple, and I have detailed the setup procedure in
the
README.md
file which can be found in the respective GitHub repository. After you
provided the necessary authentication information, you can run it from
your terminal via
python ./twitter_timeline.py --out 'output.csv'
in order to save your timeline in CSV format.
Alternatively, you can import the TimelineMiner class from the
twitter_timeline.py to run the code directly in this IPython notebook
as shown below.
import sys
sys.path.append('../../twitter_timeline/')
import twitter_timeline
import oauth_info as auth
tm = twitter_timeline.TimelineMiner(auth.ACCESS_TOKEN,
auth.ACCESS_TOKEN_SECRET,
auth.CONSUMER_KEY,
auth.CONSUMER_SECRET,
auth.USER_NAME
)
print('Authentification successful: %s' %tm.authenticate())
tm.get_timeline(max=2000, keywords=[])
Authentification successful: True
Tweets downloaded: 1999
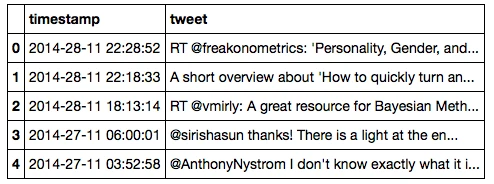
If you used twitter_timeline.py from the terminal terminal, you can
read the “tweets” from the CSV file via
import pandas as pd
df = pd.read_csv('path/to/CSV')
B. Creating the Word Cloud
Now that we collected the tweets from our twitter timeline the creation
of the word cloud is pretty simple and straightforward thanks to the
nice wordcloud module.
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
# join tweets to a single string
words = ' '.join(tm.df['tweet'])
# remove URLs, RTs, and twitter handles
no_urls_no_tags = " ".join([word for word in words.split()
if 'http' not in word
and not word.startswith('@')
and word != 'RT'
])
wordcloud = WordCloud(
font_path='/Users/sebastian/Library/Fonts/CabinSketch-Bold.ttf',
stopwords=STOPWORDS,
background_color='black',
width=1800,
height=1400
).generate(no_urls_no_tags)
plt.imshow(wordcloud)
plt.axis('off')
plt.savefig('./my_twitter_wordcloud_1.png', dpi=300)
plt.show()

Surprise, surprise: The most common term I used in my tweets is obviously “Python!”
To make the word cloud even more visually appealing, let us use a custom shape in form of the twitter logo:
from scipy.misc import imread
twitter_mask = imread('./twitter_mask.png', flatten=True)
wordcloud = WordCloud(
font_path='/Users/sebastian/Library/Fonts/CabinSketch-Bold.ttf',
stopwords=STOPWORDS,
background_color='white',
width=1800,
height=1400,
mask=twitter_mask
).generate(no_urls_no_tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.savefig('./my_twitter_wordcloud_2.png', dpi=300)
plt.show()

(You can find the twitter_mask.png
here)
{kind=link}
Optionally, you can add additional stop words to the STOPWORD set to
be ignored when building the word cloud:
more_stopwords = {'oh', 'will', 'hey', 'yet', ...}
STOPWORDS = STOPWORDS.union(more_stopwords)
I wrote this simple twitter timeline mining code in a completely different context, and I luckily found out about this neat wordcloud module when I was working on a data mining project about song lyrics classification by mood. However, I have to say that I find this particularly combination very interesting, and I was curious to get an “objective” about my twitter language and topics! I hope you found this short tutorial interesting and I am looking forward to seeing some of your word clouds on twitter!
Read Next
 Scientific Computing in Python: Introduction to NumPy and Matplotlib
Beginner's guide to NumPy and Matplotlib for scientific computing: arrays, indexing, broadcasting, linear algebra, and plotting with Python code examples.
Scientific Computing in Python: Introduction to NumPy and Matplotlib
Beginner's guide to NumPy and Matplotlib for scientific computing: arrays, indexing, broadcasting, linear algebra, and plotting with Python code examples.
 Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
 Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...
Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!