SQLite
– Working with large data sets in Python effectively
My new project confronted me with the task of screening a massive set of large data files in text format with billions of entries each. I will have to retrieve data repeatedly and frequently in the future. Thus, I was tempted to find a better solution than brute-force scanning through ~20 separate 1-column text files with ~6 billion entries every time line by line.e.
OVERVIEW
At the end of the day, I wanted to have a unified database structure that combines all those columns, which represent different features currently listed in those separate text files. This database should be extendable, and my workflow will require that I can efficiently pull out entries with intersecting features for further computation.
So I’ve been looking around, and it was not too long until I stumbled upon this awesome sqlite3 Python module for working with SQLite database structures. Fortunately, you don’t have to be an SQL expert to dive in. The sqlite3 module documentation is really well written and will serve you as a good point of entry: http://docs.python.org/2/library/sqlite3.html
![]()
SQLite is an open-source database engine ideal for smaller workgroups because it is a single locally stored database file that does not require any server infrastructure.
Furthermore, SQLite works on all common operating systems and is compatible with 32bit and 64bit machines. Plenty of applications let you use the powerful SQL syntax, and SQLite has gained a reputation of being very reliable as it is used by popular companies, such as Google, Mozilla, Adobe, Apple, Microsoft, etc. The only downside I could find was that there is a size limit of 140 terabytes per database file, but “foreign keys” allow cross-queries between different database files, so even this size limit shouldn’t be a big concern.
If you want to learn more about SQLite, you can check out their website at http://www.sqlite.org.
sqlite3 in a nutshell
In the following section, I will present some code to show how easy it is to use the sqlite3 module in Python. I added comments with the hope of making it as self-explanatory as possible. After the code examples, I have some interesting benchmarks that demonstrate the efficiency of SQL queries.
Creating an SQLite database
import sqlite3
# create new db and make connection
conn = sqlite3.connect('my_db.db')
c = conn.cursor()
# create table
c.execute('''CREATE TABLE my_db
(id TEXT, my_var1 TEXT, my_var2 INT)''')
# insert one row of data
c.execute("INSERT INTO my_db VALUES ('ID_2352532','YES', 4)")
# insert multiple lines of data
multi_lines =[ ('ID_2352533','YES', 1),
('ID_2352534','NO', 0),
('ID_2352535','YES', 3),
('ID_2352536','YES', 9),
('ID_2352537','YES', 10)
]
c.executemany('INSERT INTO my_db VALUES (?,?,?)', multi_lines)
# save (commit) the changes
conn.commit()
# close connection
conn.close()
Note:* *As a careful reader pointed out in the comment section below, it would make sense to use integers as IDs instead of strings to increase computational efficiency - given that the relevant identifier consisted of numbers only. In the case I picked for this example (ID_2352533, ID_2352534, …), the IDs seem to follow the same pattern: “ID” + number. So instead of using it as is, we could convert it to an integer before we insert it into the database. E.g., by a simple Python expression: int(“ID_2352533”[3:])
Updating an existing database
import sqlite3
# make connection to existing db
conn = sqlite3.connect('my_db.db')
c = conn.cursor()
# update field
t = ('NO', 'ID_2352533', )
c.execute("UPDATE my_db SET my_var1=? WHERE id=?", t)
print "Total number of rows changed:", conn.total_changes
# delete rows
t = ('NO', )
c.execute("DELETE FROM my_db WHERE my_var1=?", t)
print "Total number of rows deleted: ", conn.total_changes
# add column
c.execute("ALTER TABLE my_db ADD COLUMN 'my_var3' TEXT")
# save changes
conn.commit()
# print column names
c.execute("SELECT * FROM my_db")
col_name_list = [tup[0] for tup in c.description]
print col_name_list
# close connection
conn.close()
Querying the SQLite database
import sqlite3
# open existing database
conn = sqlite3.connect('my_db.db')
c = conn.cursor()
# print all lines ordered by integer value in my_var2
for row in c.execute('SELECT * FROM my_db ORDER BY my_var2'):
print row
# print all lines that have "YES" as my_var1 value
# and have an integer value <= 7 in my_var2
t = ('YES',7,)
for row in c.execute('SELECT * FROM my_db WHERE my_var1=? AND my_var2 <= ?', t):
print row
# print all lines that have "YES" as my_var1 value
# and have an integer value <= 7 in my_var2
t = ('YES',7,)
c.execute('SELECT * FROM my_db WHERE my_var1=? AND my_var2 <= ?', t)
rows = c.fetchall()
for r in rows:
print r
# close connection
conn.close()
Benchmarks
After I tinkered with the sqlite3 module, my next important question was: How fast is SQLite really? To make some simple speed comparisons, I set up an example file of 6.1 Million lines (75 Mb) to measure the CPU time to a) read in the text file line by line with simple Python code b) read in the text file to create an SQLite database c) query the whole database.
I simply wanted to see how much I could gain by querying the database (c) instead of reading the whole file from scratch every time (a). I was also interested in how long it might take to build the SQLite database in the first place. Note that this is just a simplified example using a single text file consisting of one column. In an actual application, I would have to scan 20 files with 6 billion rows each or query 1 database with 6 billion entries in 21 columns, respectively.
Below you find the 3 short Python scripts that I used to measure the CPU time for the three scenarios a), b), and c) mentioned above.
a) read_lines.py
import time
start_time = time.clock()
lines = 0
with open("feature1.txt", "rb") as fileobj:
for line in fileobj:
lines += 1
elapsed_time = time.clock() - start_time
print "Time elapsed: {} seconds".format(elapsed_time)
print "Read {} lines".format(lines)
b) create_sqlite_db.py
import sqlite3
import time
start_time = time.clock()
conn = sqlite3.connect('my_db1.db')
c = conn.cursor()
c.execute('''CREATE TABLE my_db1 (id TEXT, feature1 TEXT, feature2 INT)''')
lines = 0
lst = list()
with open("feature1.txt", "rb") as myfile:
for line in myfile:
line = line.strip()
lst.append((line, "Yes", None))
lines += 1
c.executemany("INSERT INTO my_db1 VALUES (?,?,?)", lst)
conn.commit()
conn.close()
elapsed_time = time.clock() - start_time
print "Time elapsed: {} seconds".format(elapsed_time)
print "Read {} lines".format(lines)
c) query_sqlite_db.py
import sqlite3
import time
start_time = time.clock()
conn = sqlite3.connect('my_db1.db')
c = conn.cursor()
lines = 0
lst = list()
t = ('YES',)
for row in c.execute('SELECT * FROM my_db1 WHERE feature1=?', t):
lst.append(row)
lines += 1
conn.close()
elapsed_time = time.clock() - start_time
print "Time elapsed: {} seconds".format(elapsed_time)
print "Read {} lines".format(lines)
Results and Conclusions
As you can see in the chart below, the results are really impressive, and SQLite didn’t disappoint.
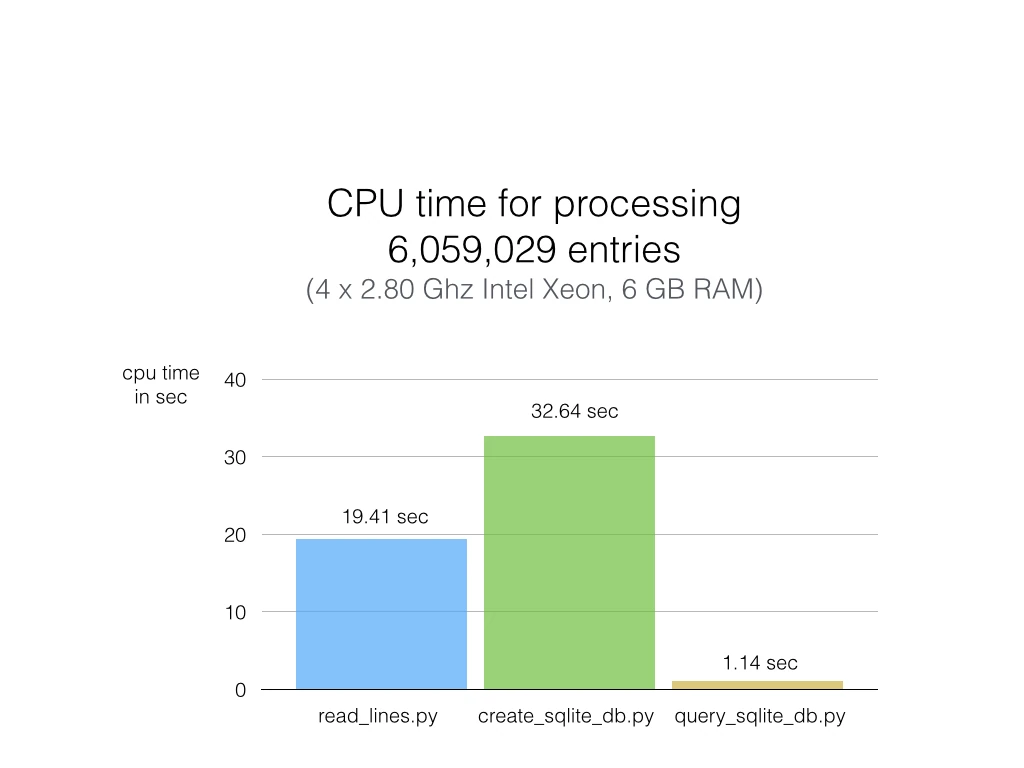
Python (on my machine) requires not more than 20 sec to go through 6 million lines of text (first column) without additional computation or analysis, however. When adding those lines to an SQLite database, the CPU time increases by one-third (second column). Reading the text file line by line is definitely faster than I expected, but sqlite3 puts the plain Python code in the shade: Querying my whole 6-million-entries-database and pulling out ALL of them takes about 1 second (third column)! That is approximately 20x faster than Python code scanning a plain text file (remember that 1 has 20 text files, and each is 1000x larger than this example file).
If we were to make a very simplified comparison, imagine it would take Python ~5 min to go through every real data set file, and I have 20 of them. If I cross-compare the data for intersecting features, I would easily end up with > 2 h of CPU time. And this process would have to repeat every time I set up a new screening. But if I had my SQLite database, I could do the same thing in < 1 min. So for screening daily, after the first week, I could already come down to 10 h Python line-by-line screening VS. 5 min SQL queries. I think it is just awesome.
Read Next
 Scientific Computing in Python: Introduction to NumPy and Matplotlib
Beginner's guide to NumPy and Matplotlib for scientific computing: arrays, indexing, broadcasting, linear algebra, and plotting with Python code examples.
Scientific Computing in Python: Introduction to NumPy and Matplotlib
Beginner's guide to NumPy and Matplotlib for scientific computing: arrays, indexing, broadcasting, linear algebra, and plotting with Python code examples.
 Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
Model evaluation, model selection, and algorithm selection in machine learning
Part 4 of the model evaluation series explaining statistical tests, algorithm comparisons, corrected resampled tests, and nested cross-validation.
 Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...
Generating Gender-Neutral Face Images with Semi-Adversarial Neural Networks to Enhance Privacy
I thought that it would be nice to have short and concise summaries of recent projects handy, to share them with a more general audience, including...

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!