Hello, I'm Sebastian Raschka, PhD
I am an LLM Research Engineer with over a decade of experience in artificial intelligence. My work bridges academia and industry, including roles as senior engineer at Lightning AI and as a statistics professor at the University of Wisconsin-Madison.
I am also the author of Build a Large Language Model (From Scratch).
My expertise lies in LLM research and the development of high-performance AI systems, with a deep focus on practical, code-driven implementations. (For my most up-to-date CV details, please visit my LinkedIn profile.)

Recent Articles and Notes
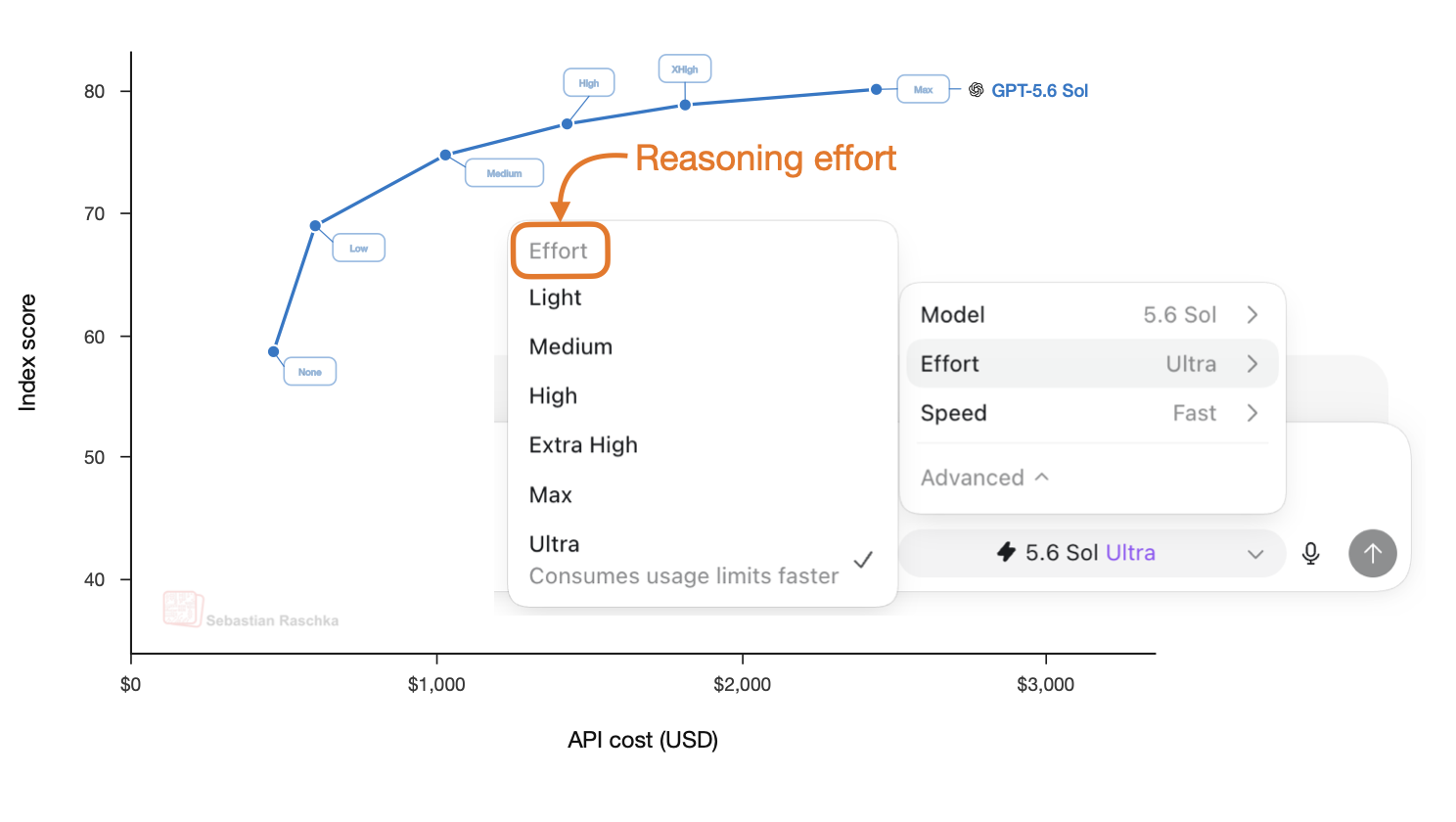
Jul 18, 2026
How LLMs Learn Low-, Medium-, and High-Effort Reasoning Modes
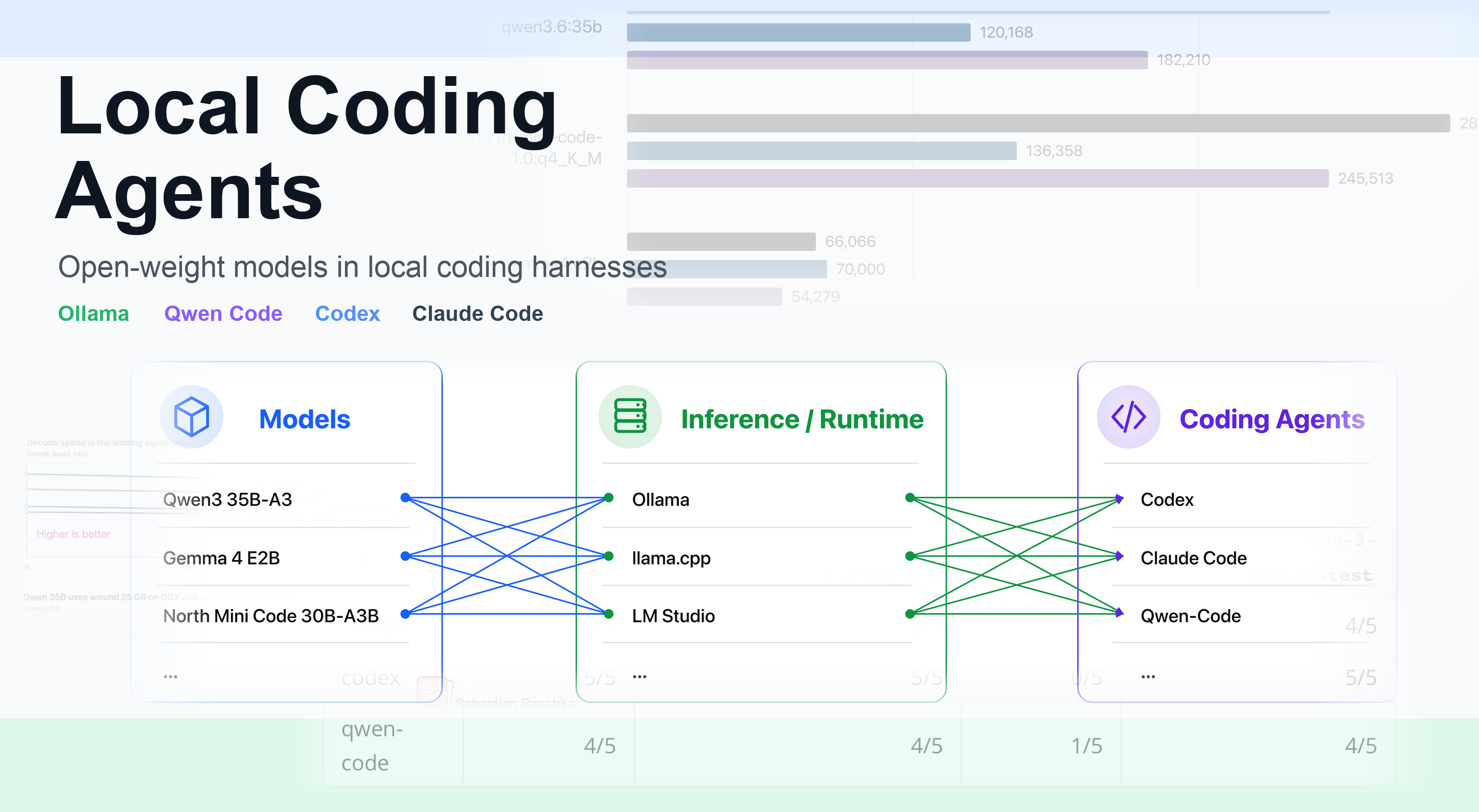
Jun 27, 2026
Using Open-Weight Models in Local Coding Harnesses as an Alternative to Claude Code and Codex Subscriptions
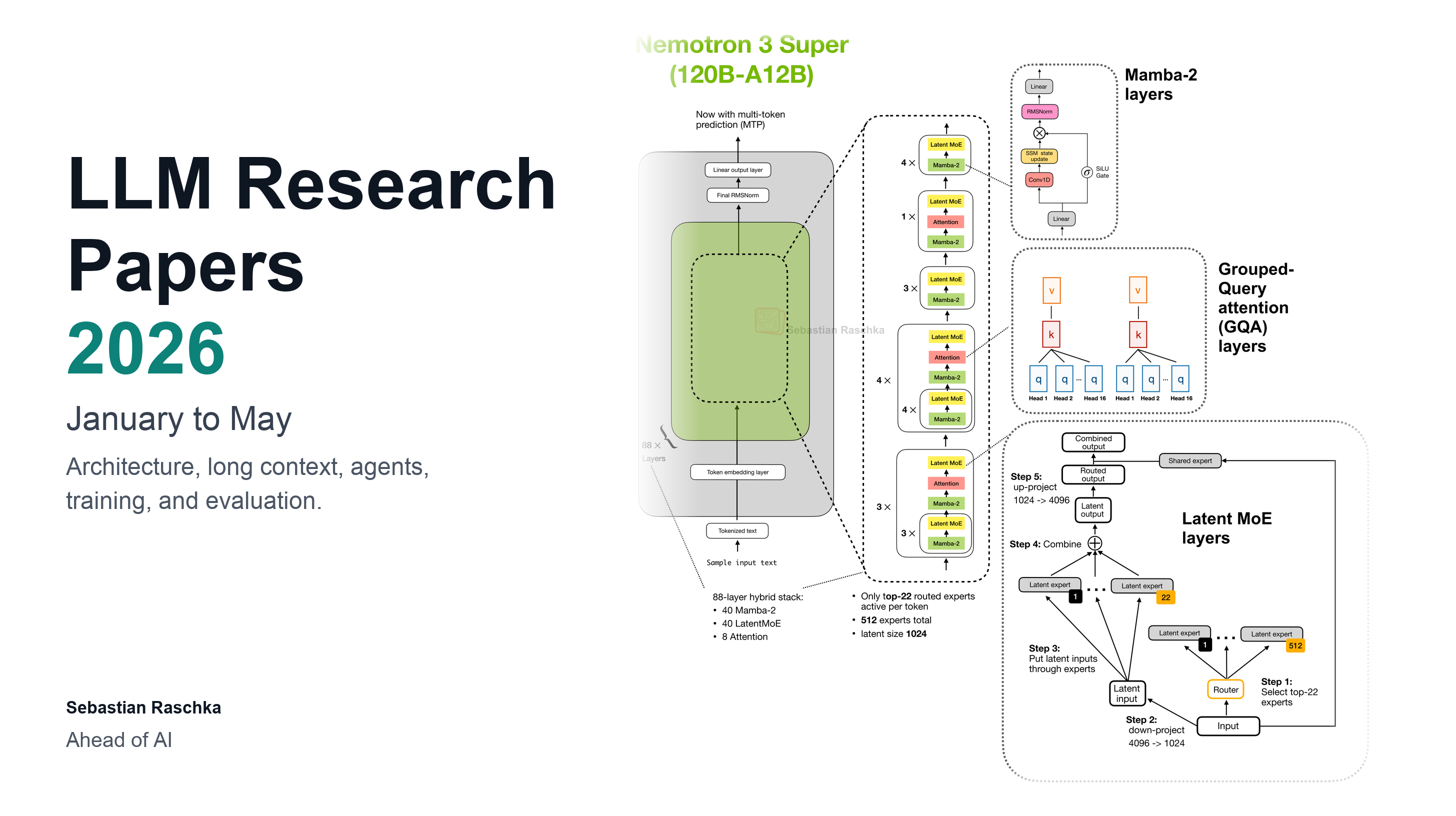
Jun 6, 2026
A curated roundup of notable LLM research papers that came out this year

May 16, 2026
From Gemma 4 to DeepSeek V4, How New Open-Weight LLMs Are Reducing Long-Context Costs
Short correction note for the random seed in Listing 6.5 on page 198 of Build a Reasoning Model From Scratch.
Short note on Thinking Machines Lab's 975B Inkling model, including benchmarks, sparse MoE design, short convolutions, RMSNorm, and posit...
Short note celebrating Ahead of AI reaching 200,000 subscribers.
Short note on how GPT 5.6 model and effort choices map onto training-time and inference-time scaling, producing 72 configurations.
Short note announcing the release of Build a Reasoning Model From Scratch and linking the publisher and Amazon pages.