A Short Chronology Of Deep Learning For Tabular Data
[Last updated: Jan 23, 2023]
In my lectures, I emphasize that deep learning is really good for unstructured data (essentially, that’s the opposite of tabular data). Deep learning is sometimes referred to as “representation learning” because its strength is the ability to learn the feature extraction pipeline. Most tabular datasets already represent (typically manually) extracted features, so there shouldn’t be a significant advantage using deep learning on these.
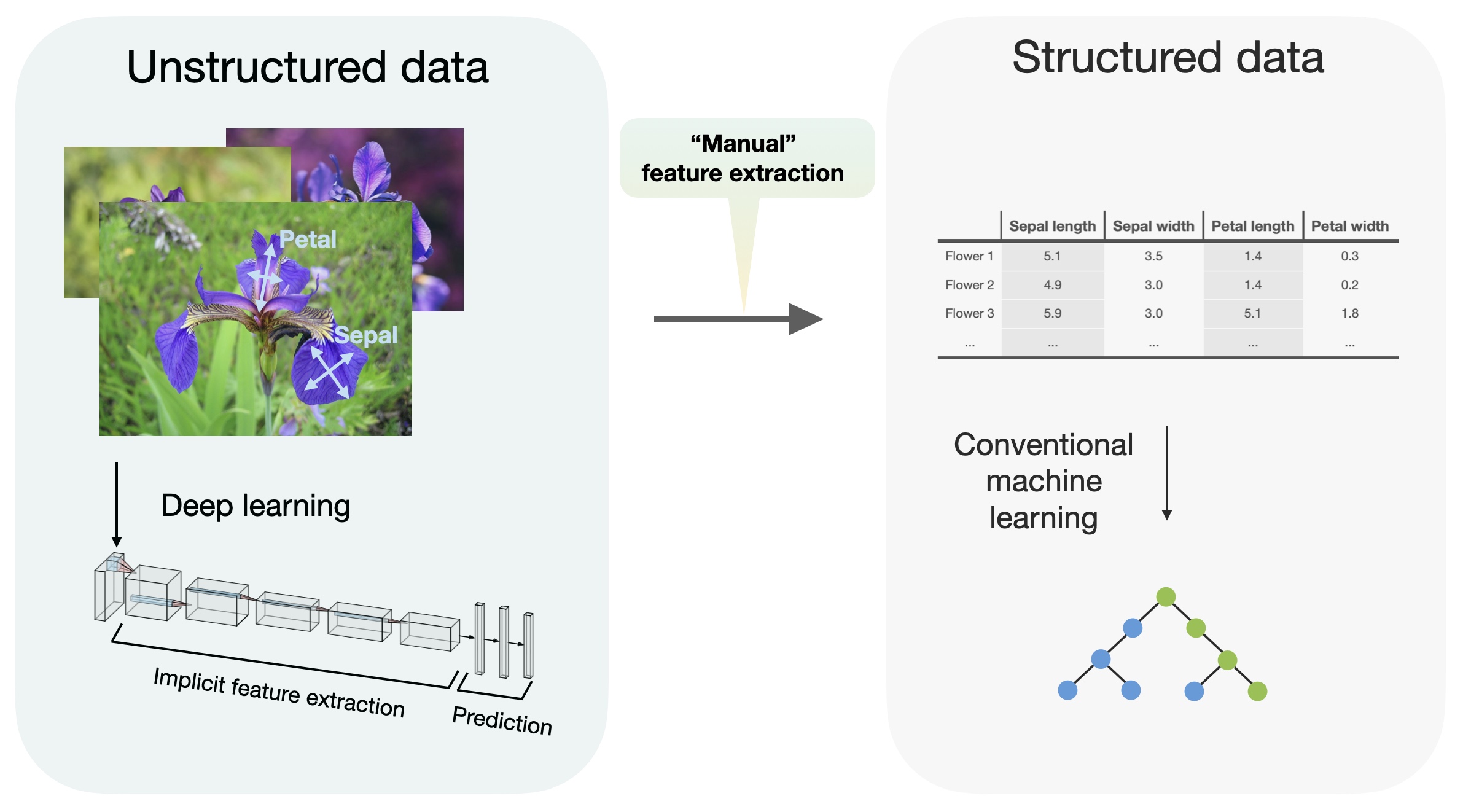
Nonetheless, many researchers recently tried developing special-purpose deep learning methods for tabular datasets. Occasionally, I share research papers proposing new deep learning approaches for tabular data on social media, which is typically an excellent discussion starter. Often, people ask for additional methods or counterexamples. So, with this short post, I aim to briefly summarize the major papers on deep tabular learning I am currently aware of. It is possible that I skipped or forgot a few. I am happy to curate and update this list for future reference, so please let me know if there is something I missed.
(By the way, many earlier papers use multilayer perceptrons on tabular datasets and refer to it as “deep learning” – several computational biology papers that train multilayer perceptrons on molecular fingerprint data come to mind. However, to me, multilayer perceptrons are not really “deep learning,” so I am not listing those.)
I want to emphasize that no matter how interesting or promising deep tabular methods look, I still recommend using a conventional machine learning method as a baseline. There is a reason why I cover conventional machine learning before deep learning in my book.
Deep Learning For Tabular Data In Reverse Chronological Order
Below is a (growing) list of relevant papers along with links and short summaries. I will try to keep this list up to date as new publications arrive. Please let me know if you know of some additional papers I may have missed!
Please note that I am excluding the following topics from this list since they are slightly out of scope:
- Classic deep learning methods (plain multilayer perceptrons, etc.);
- Methods developed for time series data;
- Methods related to recommender systems.
[Last updated: November 21, 2022]
Sections
- Deep Learning For Tabular Data In Reverse Chronological Order
- Sections
- Language Models Are Realistic Tabular Data Generators (2022-10)
- TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second (2022-10)
- TabDDPM: Modelling tabular data with diffusion models (2022-09)
- Why do tree-based models still outperform deep learning on tabular data? (2022-07)
- GATE: Gated Additive Tree Ensemble for Tabular Classification and Regression (2022-07)
- Revisiting Pretraining Objectives for Tabular Deep Learning (2022-07)
- Transfer Learning with Deep Tabular Models (2022-06)
- Scalable Interpretability via Polynomials (2022-06)
- Hopular: Modern Hopfield Networks for Tabular Data (2022-06)
- Neural Basis Models for Interpretability (2022-05)
- On Embeddings for Numerical Features in Tabular Deep Learning (2022-03)
- DANETs: Deep Abstract Networks for Tabular Data Classification and Regression (2021-12)
- Deep Neural Networks and Tabular Data: A Survey (2021-10)
- ARM-Net: Adaptive Relation Modeling Network for Structured Data (2021-07)
- SCARF: Self-Supervised Contrastive Learning using Random Feature Corruption (2021-06)
- Revisiting Deep Learning Models for Tabular Data (2021-06)
- Well-tuned Simple Nets Excel on Tabular Datasets (2021-06)
- XBNet: An Extremely Boosted Neural Network (2021-06)
- Tabular Data: Deep Learning is Not All You Need (2021-06)
- Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning (2021-06)
- SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training (2021-06)
- Denoising Autoencoders (DAEs) for Tabular Data (2021-04)
- Converting Tabular Data Into Images for Deep Learning with Convolutional Neural Networks (2021-02)
- TabTransformer: Tabular Data Modeling Using Contextual Embeddings (2020-12)
- VIME: Extending the Success of Self- and Semi-supervised Learning to Tabular Domain (2020-06)
- A Novel Method for Classification of Tabular Data Using Convolutional Neural Networks (2020-05)
- Neural Additive Models: Interpretable Machine Learning with Neural Nets (2020-04)
- Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data (2019-09)
- TabNet: Attentive Interpretable Tabular Learning (2019-08)
- SuperTML: Two-Dimensional Word Embedding for the Precognition on Structured Tabular Data (2019-02)
- Tools & Benchmarks
- Conclusion
[12 Oct 2022]
Language Models Are Realistic Tabular Data Generators (2022-10)
by Vadim Borisov, Katrin Sessler, Tobias Leemann, Martin Pawelczyk, Gjergji Kasneci
📝 Paper: https://arxiv.org/abs/2210.06280
🖥 Code: https://github.com/kathrinse/be_great
-
The GReaT (Generation of Realistic Tabular data) method uses an auto-regressive generative LLM based on self-attention to generate synthetic tabular datasets; in particular, the authors use pre-trained transformer-decoder networks (GPT-2 and the smaller Distil-GPT-2).
-
GReaT supports heterogeneous features, both discrete and numerical features, and was evaluated on four datasets: Travel customers (250k examples), HELOC (10k examples), Adult Income (50k examples), and California Housing (20k) examples.
-
The authors utilize pretrained transformers, and the procedure consists of two steps, finetuning and sampling.
-
Stage 1, finetuning: (1) transform feature vectors into text; (2) permute feature order to encode order independence; (3) use text for transformer finetuning.
-
Stage 2, sampling: pass (incomplete) inputs to finetuned transformer; (2) obtain completed feature vectors from transformer in text format; (3) transfer feature texts to tabular format.
-
In “machine learning efficiency” experiments, the authors found that classifiers trained on the artificial data perform better (and more similar to the original) when trained on GReat synthetic data compared to synthetic data from other methods.
-
Assessing how similar the synthetic data is to the original data, the “distance to closest records” diagrams show that GReaT does not copy the training data. Moreover, the authors did a “discriminator measure” study. They combined the original with the synthetic data and assigned a class label to indicate whether the data was original (0) or synthetic (1). Classifiers trained on these datasets had an average accuracy of 70%; they could tell artificial data to some extent. However, GReat faired much better than other synthetic data approaches (the accuracy ranged between 75% to 88%).
[10 Oct 2022]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second (2022-10)
by Noah Hollmann, Samuel Müller, Katharina Eggensperger, Frank Hutter
📝 Paper: https://arxiv.org/abs/2207.01848
🖥 Code: https://github.com/automl/TabPFN
🐦 Twitter: Discussion thread
-
TabPFN (tabular prior-data fitted network) is an intriguing fresh take on deep learning for tabular data, combining approximate Bayesian inference and transformer tokenization.
-
Note that while the method is based on Bayesian inference, it is well-known (see Judea Pearl’s Book of Why) that causal mechanisms can’t be obtained from observational data alone. As a clever workaround, the researchers approximate the posterior predictive distribution directly given a prior that one can sample from.
-
What makes the method particularly appealing is that it doesn’t require training, hyperparameter tuning, or cross-validation – it only requires a single forward pass on a new training set. The caveat is that it requires synthetic datasets for the prior. (Is the conventional hyperparameter tuning on a training dataset more laborious that the expensive prior-data fitting procedure? The prior fitting time is 20h on 8 GPUs.)
-
Currently, the method was evaluated on 30 small datasets (2k training examples, 100 features, 10 imbalanced classes); computationally, it does not scale well to larger datasets as it scales quadratically with the training set size.
-
Other methods such as XGBoost, LightGBM, AutoGluon were limited to 60 min computation time per dataset. Other contemporary tabular methods were not included in this benchmark. The most best performances per dataset were achieved by the TabPFN + AutoGluon combination (9) followed by AutoGluon (7) and TabPFN (6). XGBoost outperformed other methods only on 3 datasets.
-
The researchers mention that the errors are uncorrelated to those of other methods; this makes TabPFN attractive for ensembling (a potentially interesting topic for future studies).
[30 Sep 2022]
TabDDPM: Modelling tabular data with diffusion models (2022-09)
by Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko
📝 Paper: https://arxiv.org/abs/2209.15421
🖥 Code: https://github.com/rotot0/tab-ddpm
🐦 Twitter: Explanation & discussion thread
-
TabDDPM is a diffusion model for generating synthetic tabular data. It works with both categorical and continuous features.
-
TabDDPM uses multinomial diffusion for categorical (and binary) features, adding uniform noise. For continuous features, it uses the common Gaussian diffusion. The reverse diffusion process is learned via a fully connected network (multilayer perceptron).
-
The researchers evaluated TabDDPM across 15 classification and regression datasets, ranging from 856 to 157,638 training examples.
-
The qualitative comparison showed that the distribution of the synthetic data via TabDDPM resembled the training data distribution most closely compared to other techniques such as TVAE, CTABGAN, CTABGAN+, and SMOTE.
-
In a “machine learning efficiency” comparison, the researchers trained different models (random forest, logistic regression, decision trees, and CatBoost) on the synthetic data. In most cases, the TabDDPM data helped the models achieve a better prediction performance than the other methods.
-
Lastly, an analysis showed that TabDDPM features are less similar to the training data points compared to SMOTE, indicating that it does not just memorize data. (Caveat: the GAN- and VAE-based methods were not included in this analysis.)
[18 Jul 2022]
Why do tree-based models still outperform deep learning on tabular data? (2022-07)
by Léo Grinsztajn, Edouard Oyallon, Gaël Varoquaux
📝 Paper: https://arxiv.org/abs/2207.08815
🖥 Code: https://github.com/LeoGrin/tabular-benchmark
🐦 Twitter: Explanation & discussion thread
-
The main takeaway is that tree-based models (random forests and XGBoost) outperform deep learning methods for tabular data on medium-sized datasets (10k training examples).
-
The gap between tree-based models and deep learning becomes narrower as the dataset size increases (here: 10k -> 50k).
-
Solid experiments and thorough investigation into the role of uninformative features: uninformative features harm deep learning methods more than tree-based methods.
-
Small caveats: some of the recent tabular methods for deep learning were not considered; “large” datasets are only 50k training examples (small in many industry domains.)
-
Experiments based on 45 tabular datasets; numerical and mixed numerical-categorical; classification and regression datasets; 10k training examples with balanced classes for main experiments; 50k datasets for “large” dataset experiments.
[18 Jul 2022]
GATE: Gated Additive Tree Ensemble for Tabular Classification and Regression (2022-07)
by Manu Joseph, Harsh Raj
📝 Paper: https://arxiv.org/abs/2207.08548
🖥 Code: https://github.com/manujosephv/GATE
-
In essense, GATE can be understood as a hierachical stacking of decision tree stumps.
-
Similar to NODE (described further below) the proposed GATE method is based on differentiable decision trees. In addition, the GATE architecture is inspired by the GRU gating mechanisms and also includes self-attention for (re)weighting the outputs.
-
Across 5 large datasets (3 classification and 2 regression datasets, ranging from 26M to 800 M training examples), GATE achieved the highest average rank (tied with LightGBM).
-
The paper comes without code, so we have to accept the results with some reservations.
[7 Jul 2022]
Revisiting Pretraining Objectives for Tabular Deep Learning (2022-07)
by Ivan Rubachev, Artem Alekberov, Yury Gorishniy, Artem Babenko
📝 Paper: https://arxiv.org/abs/2207.03208
🖥 Code: https://github.com/puhsu/tabular-dl-pretrain-objectives
-
In contrast to most tree-based methods (like the default implementations of gradient boosting machines), deep neural networks can be trained iteratively and support pretraining. In this paper, the authors study the different pretraining strategies for deep tabular methods.
-
Pretraining is already standard for computer vision and natural language processing, where models are pretraining on additional (typically unlabeled) data. The authors use the target dataset for pretraining instead of additional data.
-
The authors focus on multilayer perceptrons and study various pretraining schemes: self-prediction vs. contrastive methods, masked-based self-prediction vs. reconstruction, and target-aware vs. target agnostic.
-
The study includes 11 different datasets ranging from 6k to 723k training examples and 6 to 136 features. The datasets cover both classification and regression and numerical and categorical features.
-
In most cases, numerical embedding-based multilayer perceptrons with target-aware mask-based (self-prediction) pretraining perform best. There are only two datasets where gradient boosting (XGBoost and CatBoost) outperforms the pretrained MLPs.
[30 Jun 2022]
Transfer Learning with Deep Tabular Models (2022-06)
by Roman Levin, Valeriia Cherepanova, Avi Schwarzschild, Arpit Bansal, C. Bayan Bruss, Tom Goldstein, Andrew Gordon Wilson, Micah Goldblum
📝 Paper: https://arxiv.org/abs/2206.15306
🖥 Code: https://github.com/LevinRoman/tabular-transfer-learning
-
In contrast to gradient boosting, deep learning methods for tabular data can be pretrained on upstream data to increase performance on the target dataset.
-
Supervised pretraining is better than self-supervised pretraining in a tabular dataset context.
-
Multilayer perceptrons outperform transformer-based deep neural networks if target data is scarce.
-
Proposes a pseudo-feature method for cases where the upstream and target feature sets differ.
-
Medical diagnosis benchmark dataset; patient data with 11 diagnosis targets where features between upstream and target data are related but may differ.
[16 Jun 2022]
Scalable Interpretability via Polynomials (2022-06)
by Filip Radenovic, Abhimanyu Dubey, Dhruv Mahajan
📝 Paper: https://arxiv.org/abs/2205.14108
🖥 Code: https://github.com/facebookresearch/nbm-spam
-
Similar to the Neural Additive Model (NAM) (further below), the proposed Scalable Polynomial Additive Models (SPAM) is a type of generalized additive model and its primary goal is interpretability. However, in contrast to NAM, SPAM is easier to scale since it require an individual neural network for each feature.
-
The SPAM-Neural model (which shared the same multilayer perceptron architecture as NAM) outperformed NAM on all 3 tabular datasets and outperformed XGBoost in 2 out of 3 cases.
[1 Jun 2022]
Hopular: Modern Hopfield Networks for Tabular Data (2022-06)
by Bernhard Schäfl, Lukas Gruber, Angela Bitto-Nemling, Sepp Hochreiter
📝 Paper: https://arxiv.org/abs/2206.00664
🖥 Code: https://github.com/ml-jku/hopular
-
Proposes a new deep learning architecture for small- to medium-sized datasets based on Hopfield Networks – a form of recurrent neural networks.
-
Across 21 UCI datasets, the proposed Hopular network has the best median rank (7.5); the closest median rank is by a Non-Parametric Transformers (11.0). XGBoost has a median rank of 12.0.
-
Experiments were done on 21 UCI datasets ranging from 208 to 1000 examples. Nine datasets also contain categorical features.
-
In the article Trouble with Hopular Bojan Tunguz describes that the tree-based reference methods such as HistGradientBoosting and XGBoost were insufficiently tuned. However, when properly tuned, tree-based gradient boosting methods outperform the proposed Hopular net.
[27 May 2022]
Neural Basis Models for Interpretability (2022-05)
📝 Paper: https://arxiv.org/abs/2205.14120
🖥 Code: https://github.com/facebookresearch/nbm-spam
-
Similar to the Neural Additive Model (NAM) (further below), the Neural Basis Model (NBM) is a type of generalized additive model. Similar to NAM, its primary goal is interpretability. However, in contrast to NAM, NBM is easier to scale since it is a single neural network (vs one neural network per feature).
-
The experiments include 4 tabular datasets, 1 regression, 1 binary classification, and 2 multi-class classification datasets. The dataset sizes range from 7k to 406k training examples.
-
The NBM outperforms the NAM on all tabular datasets (except 1 dataset for which NAM results were not available). While the NBM predictive performance is substantially worse than XGBoost, it outperforms Explainable Boosting Machines in all cases.
[15 Mar 2022]
On Embeddings for Numerical Features in Tabular Deep Learning (2022-03)
by Yury Gorishniy, Ivan Rubachev, Artem Babenko
📝 Paper: https://arxiv.org/abs/2203.05556
🖥 Code: https://github.com/Yura52/tabular-dl-num-embeddings
-
Instead of designing new architectures for end-to-end learning, the authors focus on embedding methods for tabular data: (1) a piecewise linear encoding of scalar values and (2) periodic activation-based embeddings.
-
Experiments show that the embeddings are not only beneficial for transformers but other methods as well – multilayer perceptrons are competitive to transformers when trained on the proposed embeddings.
-
Using the proposed embeddings, ResNet, multilayer perceptrons, and transformers outperform CatBoost and XGBoost on several (but not all) datasets.
-
Small caveat: I would have liked to see a control experiment where the authors trained CatBoost and XGboost on the proposed embeddings.
[06 Dec 2021]
DANETs: Deep Abstract Networks for Tabular Data Classification and Regression (2021-12)
by Jintai Chen, Kuanlun Liao, Yao Wan, Danny Z. Chen, Jian Wu
📝 Paper: https://arxiv.org/abs/2112.02962
🖥 Code: https://github.com/WhatAShot/DANet
🐦 Twitter: Explanation & discussion thread
-
The DANets architecture is centered around a newly proposed Abstract Layer (ABSTLAY) that is focused on two main steps: 1) feature selection and 2) feature abstraction.
-
The core idea behind ABSTLAY is to group correlated features (via a sparse learnable mask) and create higher-level, abstract features from these.
-
Steps 1 and 2 above are grouped into a block, and the DANet architecture then consists of a stacking of such blocks.
-
The ABSTLAY itself consists of the learnable sparse mask as mentioned above; in addition it has a shortcut connection that adds the raw features back to each block (it is analogous to the shortcut connection in ResNet, however, ResNet adds the previous instead of the raw features back).
-
While the architecture can’t handle categorical features implicitely, the authors used a leave-one-out encoding from scikit-learn for categorical feature encoding.
-
The method was evaluated on 4 classification and 3 regression datasets, and the DANet-32 architecture achived the best performance on 4 out of 7 datasets.
[5 Oct 2021]
Deep Neural Networks and Tabular Data: A Survey (2021-10)
by Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawelczyk, Gjergji Kasneci
📝 Paper: https://arxiv.org/abs/2110.01889
🖥 Code: https://github.com/kathrinse/TabSurvey
-
A survey paper that investigates and compares deep neural networks proposed for tabular datasets.
-
The paper is accompanied by benchmark code, and since the paper does not propose a new method for tabular data, the results may be more objective than others.
-
Based on the results, gradient-boosted tree ensembles still mostly outperform deep learning methods on tabular datasets.
[5 Jul 2021]
ARM-Net: Adaptive Relation Modeling Network for Structured Data (2021-07)
by Shaofeng Cai, Kaiping Zheng, Gang Chen, H. V. Jagadish, Beng Chin Ooi, Meihui Zhang
📝 Paper: https://arxiv.org/abs/2107.01830
🖥 Code: https://github.com/nusdbsystem/ARM-Net
-
The proposed method transforms inputs into an exponential space and uses a sparse attention method to generate interaction weights to obtain cross-features for prediction.
-
This is essentially a transformer-inspired embedding method followed by a multilayer perceptron for prediction.
-
Besides logistic regression, the paper does not include comparisons with conventional machine learning methods.
[29 Jun 2021]
SCARF: Self-Supervised Contrastive Learning using Random Feature Corruption (2021-06)
by Dara Bahri, Heinrich Jiang, Yi Tay, Donald Metzler
📝 Paper: https://arxiv.org/abs/2106.15147
🖥 Code: N/A
-
No code available, so results are not directly reproducible and must be taken with a grain of salt.
-
The paper proposes a contrastive loss for self-supervised learning for tabular data
-
Experiments were done on 69 classification datasets, and the results showed that the self-supervised approach is an improvement compared to purely supervised approaches.
[22 Jun 2021]
Revisiting Deep Learning Models for Tabular Data (2021-06)
📝 Paper: https://arxiv.org/abs/2106.11959
🖥 Code: https://github.com/Yura52/rtdl
-
In this paper, the researchers discuss the issue of improper baselines in the deep learning for tabular data literature.
-
The main contributions of this paper are centered around two strong baselines: one is a ResNet-like architecture, and the other is a transformer-based architecture called FT-Transformer (Feature Tokenizer + Transformer).
-
Across all 11 datasets considered in this study, the FT-Transformer outperforms other deep tabular methods in 6 cases and has the best overall rank. The most competitive deep tabular method is NODE (further below), which outperforms other methods in 4 out of 11 cases.
-
In comparison with gradient boosted trees such as XGBoost and CatBoost, the FT-Transformer outperforms the former in 7 out of 11 cases; the authors conclude there is no universally superior method.
[11 Jun 2021]
Well-tuned Simple Nets Excel on Tabular Datasets (2021-06)
by Arlind Kadra, Marius Lindauer, Frank Hutter, Josif Grabocka
📝 Paper: https://arxiv.org/abs/2106.11189
🖥 Code: https://github.com/releaunifreiburg/WellTunedSimpleNets
🐦 Twitter: Explanation & discussion thread
-
Using a combination of modern regularization techniques, the authors find that simple multi-layer perceptron (MLP) can outperform both specialized neural network architectures (TabNet) and gradient boosting machines (XGBoost and Catboost)
-
The MLP base architecture consisted of 9-layers with 512 units each (excluding the output layer) and was tuned with a cosine annealing scheduler.
-
The following 13 regularization techniques were considered in this study. Implicit: (1) BatchNorm, (2) stochastic weight averaging, (3) Look-ahead optimizer. (4) Weight decay. Ensemble: (5) Dropout, (6) snapshot ensembles. Structural: (7) skip connections, (8) Shake-Drop, (9) Shake-Shake. Augmentation: (10) Mix-Up, (11) Cut-Mix, (12) Cut-Out, (13) FGSM adversarial learning
-
The comparison spans 40 tabular datasets for classification, ranging from 452 to 416,188 examples. In 19 out of the 40 datasets, an MLP with a mix regularization techniques outperformed any other method evaluated in this study.
-
Caveats: the authors included NODE in the comparison but used did not tune its hyperparameters. Also, the regularization techniques were not applied to the other neural network architectures (TabNet and NODE).
[9 Jun 2021]
XBNet: An Extremely Boosted Neural Network (2021-06)
by Tushar Sarkar
📝 Paper: https://arxiv.org/abs/2106.05239
🖥 Code: https://github.com/tusharsarkar3/XBNet
-
The method is centered around using XGBoost models and their feature importances to initialize neural network layers.
-
For the initialization, it first trains XGBoost models and derives the feature importances. Secondly, it uses the feature importances to initialize the weights of a multilayer perceptron
-
After the initialization, the method trains an additional XGBoost model for each intermediate layer. Consequently, each layer consists of a weight matrix (corresponding to the fully-connected neural network layer) and a XGBoost model; during backpropagation the feature importances are used to update the neural network weights.
-
The proposed XGBnet method was evaluated on 8 small datasets, including the classic Iris and Wine datasets. XGBNet outperformed XGBoost on 3 out of the 8 datasets.
[6 Jun 2021]
Tabular Data: Deep Learning is Not All You Need (2021-06)
by Ravid Shwartz-Ziv, Amitai Armon
📝 Paper: https://arxiv.org/abs/2106.03253
🖥 Code: N/A
-
This paper compares XGBoost and deep learning architectures for tabular data; no new method is proposed here.
-
The results show that XGBoost performs better than most deep learning methods across all datasets; however, while no deep learning dataset performs well across all datasets, a deep learning method usually performs better than XGBoost (except on one dataset). The takeaway is that across different tasks, XGBoost performs most consistently well.
-
Another takeaway is that XGBoost requires substantially less hyperparameter tuning to perform well, which is a significant benefit in many real-life scenarios.
-
The experiments with various ensembles are worth highlighting: The best results are achieved when deep neural networks are combined with XGBoost.
-
No code examples are available, so everything in this paper must be taken with a large grain of salt.
[4 Jun 2021]
Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning (2021-06)
by Jannik Kossen, Neil Band, Clare Lyle, Aidan N. Gomez, Tom Rainforth, Yarin Gal
📝 Paper: https://arxiv.org/abs/2106.02584
🖥 Code: https://github.com/OATML/Non-Parametric-Transformers
-
Proposes a deep learning method (non-parametric transformers, NPT) that processes the whole dataset simultaneously. (Note that SAINT, uploaded two days earlier, also performs attention across both rows and columns.)
-
In the NPT, self-attention is used across data points (rows) and features (columns)
-
On binary classification datasets, the NPT has the best average rank among all methods; on multi-classification datasets, NPT and XGBoost are tied; on regression tasks, NPT and XGBoost are also tied but outperformed by CatBoost.
-
Considering the self-attention between data points is a paradigm shift that appears strange and limited at first glance. However, making predictions on new, single data points is possible. The requirement is that the training dataset needs to be used as context. This is somewhat analogous to nearest-neighbor methods such as k-nearest neighbors and hence not an entirely new paradigm.
-
Beyond tabular datasets, the authors also compare their self-attention-based architecture on small image datasets such as CIFAR-10.
[2 Jun 2021]
SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training (2021-06)
by Gowthami Somepalli, Micah Goldblum, Avi Schwarzschild, C. Bayan Bruss, Tom Goldstein
📝 Paper: https://arxiv.org/abs/2106.01342
🖥 Code: https://github.com/somepago/saint
-
The Self-Attention and Intersample Attention Transformer (SAINT) hybrid architecture is based on self-attention that applies attention across both rows and columns.
-
Also proposes a self-supervised learning technique for pre-training under scarce data regimes.
-
When looking at the average performance across all nine datasets, the proposed SAINT method tends to outperform gradient-boosted trees. The datasets ranged from 200 to 495,000 examples.
[Apr 2021]
Denoising Autoencoders (DAEs) for Tabular Data (2021-04)
📝 References: https://www.kaggle.com/competitions/tabular-playground-series-apr-2021/discussion/230013…
🖥 Code: https://github.com/ryancheunggit/Denoise-Transformer-AutoEncoder
-
This method is based on using a Denoising Autoencoder (DAE) to encode tabular data so that it can be used by a linear classification layer or any other classification model.
-
The DAE-based embeddings are produced by deep neural networks. For example, the DAE can be based on Transformer-based encoding modules.
-
While I can’t find an original article introducing this method, it has won several Kaggle competions in previous years, for example: Porto Seguro’s Safe Driver Prediction and Tabular Playground Series - Feb 2021. (If someone knows an article that introduces this method, please let me know.)
[1 Feb 2021]
Converting Tabular Data Into Images for Deep Learning with Convolutional Neural Networks (2021-02)
by Yitan Zhu, Thomas Brettin, Fangfang Xia, Alexander Partin, Maulik Shukla, Hyunseung Yoo, Yvonne A. Evrard, James H. Doroshow, Rick L. Stevens
📝 Paper: https://www.nature.com/articles/s41598-021-90923-y
🖥 Code: https://github.com/zhuyitan/IGTD
-
The image generator for tabular data (IGTD) seems to take a similar approach to SuperTML (further below) in encoding tabular datasets as 2D images as input to convolutional networks. It also seems to be similar to the earlier TAC (TAbular Convolution) method (also below).
-
Interestingly, the authors omitted a comparison with SuperTML.
-
A CNN with the IGTD-based images outperforms XGBoost and LightGBM.
[11 Dec 2020]
TabTransformer: Tabular Data Modeling Using Contextual Embeddings (2020-12)
by Xin Huang, Ashish Khetan, Milan Cvitkovic, Zohar Karnin
📝 Paper: https://arxiv.org/abs/2012.06678
🖥 Code: N/A
-
Several open-source implementations are available on GitHub, however, I could not find the official implementation, so the results from this paper must be taken with a grain of salt.
-
The paper proposes a transformer-based architecture based on self-attention that can be applied to tabular data.
-
In addition to the purely supervised regime, the authors propose a semi-supervised approach leveraging unsupervised pre-training.
-
Looking at the average AUC across 15 datasets, the proposed TabTransformer (82.8) is on par with gradient-boosted trees (82.9).
[5 Jun 2020]
VIME: Extending the Success of Self- and Semi-supervised Learning to Tabular Domain (2020-06)
by Jinsung Yoon, Yao Zhang, James Jordon, Mihaela van der Schaar
📝 Paper: https://proceedings.neurips.cc/paper/2020/hash/7d97667a3e056acab9aaf653807b4a03-Abstract.html
🖥 Code: https://github.com/jsyoon0823/VIME
-
VIME (Value Imputation and Mask Estimation) includes self- and semi-supervised learning frameworks for tabular data.
-
The authors provide good ablation studies showing that the semi-supervised learning variant of VIME is better than the supervised-only and self-supervised-only variants. The best VIME variant uses both self- and semi-supervised learning and outperforms XGBoost on all datasets.
-
The comparison is based on only five datasets.
[3 May 2020]
A Novel Method for Classification of Tabular Data Using Convolutional Neural Networks (2020-05)
by Ljubomir Buturović, Dejan Miljković
📝 Paper: https://www.biorxiv.org/content/10.1101/2020.05.02.074203v1.abstract
🖥 Code: N/A
-
Similar to SuperTML (listed below), this method converts tabular data into an image format as input to conventional convolutional neural networks for image data.
-
The researchers applied this method to a gene classification dataset. They found that the TAC approach (91.1% accuracy) slightly outperforms other non-deep learning methods: Linear SVM (89.6% accuracy), XGBoost (87.6% accuracy), and others.
-
TAC was pretrained on a combination of image datasets to achieve this performance – a TAC baseline without pre-training is not provided.
-
The paper comes without code, so we have to accept the results with some reservations.
[29 Apr 2020]
Neural Additive Models: Interpretable Machine Learning with Neural Nets (2020-04)
📝 Paper: https://arxiv.org/abs/2004.13912
🖥 Code: https://github.com/google-research/google-research/tree/master/neural_additive_models
-
The proposed Neural Additive Models (NAMs) are essentially an ensemble of multilayer perceptrons (MLPs); here, one MLP is used per input feature.
-
Each MLP has precisely one input node and one output node, but it can have an arbitrary number of hidden layers and nodes. The output values are then summed and passed to a logistic sigmoid function for binary classification. (For regression, the sigmoid activation can be omitted).
-
The main advantage of this method is its ease of interpretability since each input feature is handled independently by a different neural network; i.e., the contribution of each individual feature towards the overall output (which is computed as a simple sum) can be easily assessed.
-
The NAM was evaluated on 4 datasets (2 classification and 2 regression datasets). While it performed slightly worse than XGBoost across all four datasets, it performed better than Explainable Boosting Machines on 2 out of the 4 datasets.
[13 Sep 2019]
Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data (2019-09)
by Sergei Popov, Stanislav Morozov, Artem Babenko
📝 Paper: https://arxiv.org/abs/1909.06312
🖥 Code: https://github.com/Qwicen/node
-
The proposed Neural Oblivious Decision Ensembles (NODE) method combines decision trees and deep neural networks such that they are trainable (via gradient-based optimization) in an end-to-end fashion.
-
The method is based on so-called oblivious decision trees (ODTs), a particular type of decision tree that “use the same splitting feature and splitting threshold in all internal nodes of the same depth.”
-
The experiments were conducted on six large datasets, ranging from 400K to 10.5M training examples.
-
NODE slightly outperforms XGBoost on all six datasets when default hyperparameters are used; with tuned hyperparameters, NODE outperforms XGBoost in 4 out of 6 cases.
-
The training speed of NODE (7min 42s) is about 7x slower than XGBoost (1min 13s) using a 1080Ti GPU; in inference, NODE (8.56s) is about 2x slower than XGBoost (4.45s).
[20 Aug 2019]
TabNet: Attentive Interpretable Tabular Learning (2019-08)
by Sercan O. Arik, Tomas Pfister
📝 Paper: https://arxiv.org/abs/1908.07442
🖥 Code: https://github.com/google-research/google-research/tree/master/tabnet
-
Based on my personal experience, TabNet is the first deep learning architecture for tabular data that gained widespread attention (no pun intended).
-
TabNet is based on a sequential attention mechanism, showing that self-supervised learning with unlabeled data can improve the performance over purely supervised training regimes in tabular settings.
-
Across six synthetic datasets, TabNet outperforms other methods on 3 out of 6 cases. However, XGBoost was omitted, and the tree-based reference method is extremely randomized trees rather than random forests.
-
Across 4 KDD datasets, TabNet ties with CatBoost and XGboost on 1 dataset and performs almost as well as the gradient-boosted tree methods on the remaining three datasets.
[26 Feb 2019]
SuperTML: Two-Dimensional Word Embedding for the Precognition on Structured Tabular Data (2019-02)
by Baohua Sun, Lin Yang, Wenhan Zhang, Michael Lin, Patrick Dong, Charles Young, Jason Dong
📝 Paper: https://arxiv.org/abs/1903.06246
🖥 Code: No official implementation
-
The proposed SuperTML method creates 2D (image-like) embeddings from tabular data
-
The 2D embeddings are then used as input for conventional convolutional neural networks.
-
The SuperTML method outperforms XGBoost on all three datasets Iris (150 examples), Wine (178 examples), and Adult (48,842 examples).
-
Caveat: this is a very limited selection of datasets.
-
While there are several implementations available on GitHub, there is no official implementation by the authors, so the results cannot be easily reproduced.
Tools & Benchmarks
When it comes to code implementations of particular methods, I recommend referring to the official code repositories that were shared alongside most papers. However, there are also a few dedicated tools and libraries that are worth mentioning.
- AutoGluon (see
autogluon.tabular): A library for stack ensembling neural networks; implemented using PyTorch. - PyTorch-Tabular: A PyTorch library implementing 5 deep tabular methods (as of this writing, 09/2022).
- Auto-PyTorch: A PyTorch-based neural architecture search library for tabular datasets.
- PyTorch-widedeep: A flexible package for multimodal-deep-learning to combine tabular data with text and images using Wide and Deep models in Pytorch.
- TabularBenchmarks a fairly representative collection of datasets and benchmarks for tabular data by Bojan Tunguz (currently still a draft)
Conclusion
Personally, I find the idea of using deep learning algorithms on tabular datasets weird but interesting. That’s because I am perhaps bored with using the same methods all the time. Don’t get me wrong, these methods work. However, I am also a tinkerer and like to try new things.
Should you use deep learning for tabular datasets? Probably not. But it also probably depends on whether you are adventurous and have some time to waste.
My recommendation is always to start with a solid baseline. I would pick a random forest to begin with. Then, I would try HistGradientBoosting in scikit-learn (a powerful but easy-to-use gradient boosting implementation inspired by LightGBM). If that works well and you have the extra time, I highly recommend trying XGBoost. Only then, if you have even more extra time, feel experimental, and enjoy tinkering, I would try deep learning methods on the tabular dataset.
This blog is personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.



Your support means a great deal! Thank you!